Wiktionary:Teknikvinden
| Arkiverade diskussioner:
|
Nyskapade grammatikmallar på turkiska
redigeraHej! Jag är inte så bra på att skriva/formatera mallar här på Wiktionary, men de nyligen skapade Mall:tr-subst-k, Mall:tr-subst-v och Mall:tr-pronomen behöver bearbetas för att följa svenska Wiktionarys formspråk och struktur. Jag kan peta lite, men för det här behöver jag hjälp från någon med mer avancerad kunskap om hur vår skript brukar se ut och fungera. Mvh, Svenji (diskussion) 2 januari 2021 kl. 18.02 (CET)
- @Svenji Kika på Wiktionary:Stilguide/Grammatik/Skapa en mall. Där finns proceduren detaljerat beskrivet! ~ Dodde (diskussion) 7 januari 2021 kl. 02.30 (CET)
- Och kika även på Wiktionary:Stilguide/Grammatik/Allmänna parametrar. Där förklaras vilka parametrar som bör användas och hur. ~ Dodde (diskussion) 7 januari 2021 kl. 02.33 (CET)
- Proceduren finns kanske beskriven, men jag förstår den lika lite som om den var skriven på kinesiska. Jag har försökt modifiera andra malalr tidigare, men när man inte förstår så är det bara en gissningslek som aldrig tar slut. Svenji (diskussion) 20 januari 2021 kl. 19.31 (CET)
- Och kika även på Wiktionary:Stilguide/Grammatik/Allmänna parametrar. Där förklaras vilka parametrar som bör användas och hur. ~ Dodde (diskussion) 7 januari 2021 kl. 02.33 (CET)
Avseende tr-subst-k, så skulle jag göra de första 12 rutorna synliga alltid och bara possessiv-delen ihopfällbar. Det skulle likna vanliga ryska substantiv som луна när man kommer till sidan. Sedan skulle jag inte blanda tabellkod (som bakgrundsfärg etc.) och grammatisk logik i samma mall. Gör en mall med tabellkod som enbart tar en lång lista med parametrar, och lägg logiken i en annan mall som anropar den första. Jämför {{uk-subst}} som är av första typen och alltid tar 14 argument och {{uk-subst-m}} som är av andra typen. --LA2 (diskussion) 7 november 2021 kl. 19.55 (CET)
- @Svenji, @Dodde - Jag gjorde nu başlangıç enligt mitt förslag. Den använder
{{tr-subst}}som tar 12 parametrar och struntar i possessiv-formerna, som är nog så många och ändå finns på en.wiktionary. Bra eller dåligt? Döm själv. Men detta liknar utseendet som finns för belarusiska, ryska och ukrainska grammatikmallar. --LA2 (diskussion) 11 november 2021 kl. 00.22 (CET)- Nu har kag skapat tr-pron-pers baserat på en bearbetning av be-poron-pers. Vet inte om den behöver gömmas, tycker själv det är snyggare än den är öppen på pronomen-uppslag som oftast är rätt så kala på andra språk. 𐏐Frodlekis (✍) 12 april 2024 kl. 00.37 (CEST)
Hjälpkaoset knappast rört sedan 2008, högsta kategorin, att-göra, mm
redigeraFöreslår:
- slå ihop Wiktionary:Hjälp och Hjälp:Index under namn "Hjälp:Index"
- Verkställt. Taylor 49 (diskussion) 10 januari 2021 kl. 02.35 (CET)
- Kategori:Hjälp istället för krångligt och vilseledande dubbelprefix Kategori:Wiktionary:Hjälp
- Verkställt (nästan). Taylor 49 (diskussion) 10 januari 2021 kl. 02.35 (CET)
- ny Kategori:Uppslag dit uppslag-relaterade kategorier (enligt språk, ordklass, ämne, ...) kan flyttas från Kategori:Index som då kan innehålla kategorier såsom "Uppslag", "Hjälp", "Projektsidor", ...
döpa om Wiktionary:Projekt/Wiktionary till Wiktionary:Att-göra ... ordet "wiktionary" överanvänds och "projekt" är faktiskt en perfekt synonym alltså 3 gånger samma ort, däremot inte det som egentligen avses: att-göra-listan
SV wiktionary är en av världens bästa i fråga om uppslag, men hjälpen är i nuläget så där ... dit en företrädesvis inte ska titta. Taylor 49 (diskussion) 6 januari 2021 kl. 05.02 (CET)
- Dessutom skulle jag gärna ersätta det här tipset:
- Hjälp-namnrymden ska innehålla sidor som inte har direkt med projektet Wiktionary att göra, men ändå kan vara till hjälp för bidragsgivare och besökare på ett eller annat sätt.
- Wiktionary-namnrymden ska innehålla det som mer har med Wiktionary att göra. Viktiga huvudsidor som utgör bas för undersidor: Administration, Användare, Arkiv, Projekt, Riktlinjer, Stilguide
- med
- Wiktionary-namnrymden (projekt-namnrymden) ska innehålla sidor som har med administration, användare och behörigheter, regler och diskussioner (som inte avser en enskild sida) att göra.
- Hjälp-namnrymden ska innehålla sidor som förklarar wikitekniken för bidragsskrivare och användare.
- Appendix-namnrymden ska innehålla sidor som har med språk att göra men inte är enskilda uppslag (listor med ord, grammatik, ...)
- Verkställt. Taylor 49 (diskussion) 10 januari 2021 kl. 02.35 (CET)
- Taylor 49 (diskussion) 6 januari 2021 kl. 06.41 (CET)
- @Taylor 49
- 1. Det låter rimligt att inte ha två olika "Hjälp"-namnrymder. Jag håller med om att det är förvirrande och att undernamnrymden Wiktionary:Hjälp kan samlas under namnrymden Hjälp (och Kategori:Hjälp).
- 2. I nuläget kan man nå alla kategorier via Kategori:Index. Jag tycker att Kategori:Index är överskådlig som den är. Jag tänker också att om man skapar "Kategori:Uppslag" så skapar det också förvirring med den befintliga kategorin Kategori:Alla uppslag.
- 3. Att städa i Wiktionary- och Hjälpnamnrymden är ju ett projekt och därför underordnat Wiktionary:Projekt. Sidnamnet Wiktionary:Projekt/Wiktionary tänker jag då är logiskt med nuvarande struktur av projekt. Man kanske skulle kunna tänka sig en egen namnrymd för "Projekt" precis som man har en egen namnrymd för "Hjälp". Jag vet dock inte riktigt hur man bör avgöra om något ska ha en egen namnrymd eller inte. Man skulle också kunna tänka sig att göra ett namnbyte från "Wiktionary:Projekt" till "Wiktionary:Att göra" (utan bindestreck) om man tycker att det är mer passande - exakt ord är inte viktigt för mig, men "Wiktionary" skulle fortfarande komma dubbelt till "Wiktionary:Att göra/Wiktionary". Ett alternativ är att döpa om projektet "Wiktionary" till "Wiktionary:Projekt/Metastruktur" eller "Wiktionary:Projekt/Namnrymdstruktur" eller nåt annat.
- 4. Beskrivningen av namnrymder ska naturligtvis spegla innehållet i namnrymderna. Ändra gärna om du kommer på bättre formuleringar och uppdatera gärna om strukturen ändras. ~ Dodde (diskussion) 7 januari 2021 kl. 03.21 (CET)
- 1. Verkställt.
- 2. Senarelagt.
- 3. Jag tror inte att det finns behov för ytterligare namnrymder. Jag drar tillbaka förslaget att döpa om en enda sida och vill slå ihop Wiktionary:Projekt/Wiktionary med Wiktionary:Projekt/Appendix istället till Wiktionary:Projekt/Namnrymdstruktur för närvarande. Senare skulle jag gärna ändra Special:PrefixIndex/Wiktionary:Projekt till Special:PrefixIndex/Wiktionary:Att göra men det blir väl många undersidor (190?).
- 4. Verkställt.
- Taylor 49 (diskussion) 10 januari 2021 kl. 02.35 (CET)
- @Taylor 49 3. Att slå ihop eller organisera om bland undersidor till namnrymder ryms inom ramen för sådant man kan "vara djärv" med, om man känner att man är varm i kläderna rörande Wiktionary-strukturen, så kör på! ~ Dodde (diskussion) 25 mars 2021 kl. 21.55 (CET)
Mall "är lika med" AKK "Mall:="
redigera{{=}} Mall:%3D&diff=prev&oldid=3469683. Vad ska vara fördelen med = över =? Nackdelen med DEC-encoding är att alla sidor som använder mallen fastnar i Kategori:Sidor som använder = som en mall (borde egentligen heta "Sidor som använder 'Mall:=' för något annat än just '='"). Ingen annan wiki gör på så sätt, den motsvarande katogorin brukar vara tom och ej skapad. Vågar någon att vidhålla =? Taylor 49 (diskussion) 11 januari 2021 kl. 21.53 (CET)
- @Taylor 49, jag minns inte varför det var nödvändigt - troligen nåt med grammatikmallarna. Men grammatikmallarna har ändrats och nu används inte
{{=}}särskilt mkt, så det är nog helt okej att den bara innehåller=. Skalman (diskussion) 14 januari 2021 kl. 22.52 (CET)
- Då är det väl löst ... nu gäller det att vänta tills
{{=}}blir en parserfunktion och vi kan radera mallen. Taylor 49 (diskussion) 27 januari 2021 kl. 12.11 (CET)
- Då är det väl löst ... nu gäller det att vänta tills
- Verkställt. Taylor 49 (diskussion) 29 december 2022 kl. 02.39 (CET)
- @Taylor 49 är
{{!}}också en parserfunktion eller behövs den mallen fortfarande? ~ Dodde (diskussion) 29 december 2022 kl. 17.12 (CET)
- @Taylor 49 är
{{!}}är en parserfunktion sedan år 2014,{{=}}är en parserfunktion sedan vår 2022. mw:Help:Magic_words#Other. Taylor 49 (diskussion) 29 december 2022 kl. 17.53 (CET)
Inloggning
redigeraJag har nyligen haft problem med inloggningen ... någon loggar ut mig hela tiden, inte bara vid den här wikin, utan även annanstans. Någon har väl slarvat till det centrala inloggningssytemet. Taylor 49 (diskussion) 22 januari 2021 kl. 16.12 (CET)
Skript-hjälp
redigeraHej! Om jag vill lägga till en informationsruta till en mall, likt "not:", när mallen är i oexpanderat läge (och även kvar längst ner i expanderat), hur gör jag då? Jag vill få in texten "Verbstammen diftongeras i de fall stavelsen betonas. I övrigt gäller regelbunden konjugation.". Det gäller {{es-verb-er-dift}}. Svenji (diskussion) 4 februari 2021 kl. 17.28 (CET)
- Åter till frågan: Jag vill kunna lägga till i flera mallar av oregelbundna verb (t.ex. med stamförändringar) att de redan i oexpanderat läge förklarar för den som redan har baskunskaper att verbet följer ett av dessa undantagsmönster. Till exempel för verbet volver: "Oregelbundet: verbstammen ändras i vissa fall med diftongering där o blir till ue. Verbet har oregelbunden participform." Svenji (diskussion) 16 mars 2021 kl. 12.20 (CET)
- @Svenji, som i
{{la-subst-1}}(!colspan="3" class="min"|Ordet tillhör den första deklinationen.)? ~ Dodde (diskussion) 21 mars 2021 kl. 21.06 (CET)- Tack @Dodde, ska pilla med detta när min tentavecka är över. Svenji (diskussion) 23 mars 2021 kl. 13.40 (CET)
- @Svenji, som i
Härledning - samlat: samiska eller norska
redigeraOm jag vill ange en etymologi från norska, så använder jag språkkoden no, men jag tycker det är bättre om vi inte skiljer i härledningsmallen mellan bokmål och nynorska. Detsamma gäller lånord från samiska (i de fall det saknas vetskap om vilken samiska det först lånats från, kanske oberoende från flera). Jag vet inte hur jag ska ändra en sådan skrift i så fall (t.ex. som att grc blir grekiska). Svenji (diskussion) 16 mars 2021 kl. 12.13 (CET)
- @Svenji Kan du precisera? Varje förståeligt och rimligt förslag kan implementeras. Taylor 49 (diskussion) 10 augusti 2021 kl. 00.09 (CEST)
- @Svenji: "h-nor" och "h-smi" har lagts tillbaka. Taylor 49 (diskussion) 15 augusti 2021 kl. 18.42 (CEST)
- Ur etymologisk synvinkel lånas ord inte in från "bokmål", utan från "norska", och dessa två är skrivna varieteter av ett och samma språk. För samiskans del gäller förhållandet att vissa ord har samiskt ursprung, men vilken standardiserad varietet i den samiska språkvärlden går inte längre att precisera. Att utelämna ett sådant lånord från dess härkomst vore mycket olyckligt. Liknande fall som samiskan kommer att behövas implementeras framöver, inte minst i mitt arbete med spanskan, och dess lånord från central- och sydamerikanska språk från ursprungsbefolkningen, där ibland inte ett tydligt enskilt språk kan bestämmas. Svenji (diskussion) 16 augusti 2021 kl. 11.27 (CEST)
- @Svenji: Det finns väl massor med sidor som använder "non" men borde bättre använda "h-nor" liksom sådana som använder "smi-usm" men borde använda "h-smi". Taylor 49 (diskussion) 16 augusti 2021 kl. 12.16 (CEST)
Bugg i alla böjningsmallar
redigeraHej!
Titta på böjningsmallen i matvana. Titta i synnerhet på sista cellen (genitiv bestämd form plural).
Texten är förskjuten uppåt. I dokumentets DOM ser jag att detta beror på en överflödig P-nod.
--Andreas Rejbrand (diskussion) 21 mars 2021 kl. 19.14 (CET)
- Jag kan reproducera den: stuga men ej hund. Hur länge har den här kritiska buggen funnits? Taylor 49 (diskussion) 21 mars 2021 kl. 19.28 (CET)
- Jag tror att buggen förekommer när det finns en textruta under mallen. Jag såg den först för ett par månader sedan. --Andreas Rejbrand (diskussion) 21 mars 2021 kl. 19.45 (CET)
- Slutrapporten från buggutredningen: Wiktionary:Sandlådan Taylor 49 (diskussion) 21 mars 2021 kl. 20.18 (CET)
- Koden för förled= och not= finns i
{{grammatik-slut}}, som mycket riktigt används i stort sett i alla grammatikmallar. Den mallen har inte ändrats sedan 2018. Kan det röra sig om en parsningsbugg i MediaWiki-programvaran som uppkommit nyligen, tro? @Skalman, vad säger du? ~ Dodde (diskussion) 21 mars 2021 kl. 20.57 (CET)
- Koden för förled= och not= finns i
- Kan det vara att buggen alltid har (mycket otydligt) synts? De överflödiga tecknen är ju uppenbara. Taylor 49 (diskussion) 21 mars 2021 kl. 22.10 (CET)
- Nej, är säker på att det har sett korrekt ut tidigare. Men jag har inte granskat utseendet så exakt när det blev fel kan jag inte säga.
- Några extra mellanslag, radbrytningar o.d. i den renderade html-koden är inget att bry sig om, det är ingenting som har nån betydelse.
- Felet uppstår på grund av koden
 som skjuts in i en egen<p>-element precis efter "matvanornas" i bestämd form plural genitiv-rutan i böjningstabellen när den används på matvana. Att detta sker är ju egentligen inget konstigt - det är vad som står i mallen{{grammatik-slut}}att det ska ske på rad 1-3 (för 3= dvs. förled= i böjningsmallarna) respektive rad 5-7 (för 2= dvs. not= i böjningsmallarna).
1: <includeonly>{{ #if: {{{3|}}}
2: | 
3: {{!}}-
- Alltså: Om parametern "3" finns (eller om argumentet är en tom sträng), skjut in c följt av en radbrytning och sedan det som återfinns på rad 3 och 4.
5: -->{{ #switch:{{{2|}}}||-=|
6: #default= 
7: {{!}}-
- Samma kod med #if användes på rad 5-7 för parametern 2 (dvs. for not= i grammatikmallarna), men tomt argument "" betyder generellt "SANT" och argumentet "-" betyder generellt "FALSKT" i våra mallar, så koden ändrades till att använda "#switch" så att även not=-parametern i grammatikmallarna skulle följa det mönstret.
- Alltså: Byt ut 2 (alltså not-argumentet) mot en tom sträng om 2 är "-", annars, använd defaultvärdet:
 följt av raderna 7 t.o.m. 13. - Så vad gör
 ens i mallkoden? är en HTML-kod för "space", alltså det vanligt mellanslag. Blanksteg trimmas dock bort i mallkod, så jag GISSAR att användning av var ett hack som var nödvändigt för att tabellavgränsaren i wikisyntaxen skulle börja på en ny rad och därför kunna tolkas om till rätt HTML-kod. Men det är @Skalman som skapat mallkoden så han kan nog svara på det definitivt. - Jag gjorde en snabbtest i sandlådan och det verkar som om det bara är att ta bort
 samt den efterföljande radbrytningen på två ställen, men det kanske är något jag har missat och eftersom mallen används på så många sidor tänker jag att det ändå är bäst om Skalman kikar på det först. ~ Dodde (diskussion) 22 mars 2021 kl. 17.44 (CET)
- @Andreas Rejbrand, @Taylor 49, @Dodde: Jag har tagit bort
 nu. - Något i parsern måste ha ändrats, men jag hittar ingen dokumentation om vad det skulle kunna vara.
- Förut var det nödvändigt att ha med, för extra mellanslag/radbrytningar runt
|ignorerades, och då blev det som att{{!}}hamnade på föregående rad, och alltså förstörde tabellsyntaxen. Skalman (diskussion) 25 mars 2021 kl. 22.33 (CET)
- @Andreas Rejbrand, @Taylor 49, @Dodde: Jag har tagit bort
- @Skalman Jag har just revertertat din redigering eftersom den förvärrar buggen, se medium, Wiktionary:Sandlådan, dvs anrop då både
förled=ochnot=används. Taylor 49 (diskussion) 4 juli 2021 kl. 09.11 (CEST)
- @Skalman Jag har just revertertat din redigering eftersom den förvärrar buggen, se medium, Wiktionary:Sandlådan, dvs anrop då både
- Buggen verkar finnas kvar, se t.ex. inrikesflyg. --Andreas Rejbrand (diskussion) 26 november 2022 kl. 12.18 (CET)
- @Andreas Rejbrand Jag tror att det ska vara fixat nu. ~ Dodde (diskussion) 27 november 2022 kl. 13.36 (CET)
- Toppen, tack! --Andreas Rejbrand (diskussion) 28 november 2022 kl. 15.23 (CET)
Tagg-mallen, anrop kat=reflexivt
redigeraHej! Jag hittar inte var man redigerar i denna mallen (kanske av god anledning). Jag vill lägga till samma funktion för reflexiva verb på fornsvenska och för spanska, som vi nu har för svenska verb, d.v.s. att tagg|reflexivt visar reflexivt: raka sig. På fornsvenska grena vill jag alltså att kommandot skapar reflexivt: grena sik, och för spanska peinar reflexivt: peinarse. Svenji (diskussion) 23 mars 2021 kl. 13.48 (CET)
- Det är förmodligen i modulkoden du kan lägga till stöd för flera språk. Men det är bra att du är försiktig. Ett fel i denna påverkar hela ordboken! --Andreas Rejbrand (diskussion) 23 mars 2021 kl. 13.52 (CET)
Nya absurda buggar
redigera- Några av mina dagens redigeringar har bot-märket b fastän jag inte även har bot-flaggan på det här kontot (se Special:Senaste_ändringar)
fliken "Mer" -> "Flytta" försvann (hände igår på en annan wiki)- godtyckliga utloggningar (äldre, se #Inloggning)
Taylor 49 (diskussion) 20 april 2021 kl. 15.50 (CEST) Taylor 49 (diskussion) 22 april 2021 kl. 09.55 (CEST)
Hjälp med inställningar i redigeringsläge: färgad formatering, plus röd prick för annars "osynliga" mellanrum.
redigeraHej! Jag skulle testa lite olika utseenden, vilket resulterade i att jag fick nollställa alla inställningar. Nu märker jag till min förfäran att redigeringsläget är i svartvitt, men jag vill ha tillbaka mina gröna ref-länkar, lila och blåa webblänkar osv... Var ändrar man det? Och den lilla röda pricken som oftast döljer sig efter kopierade ord på t.ex. arabiska och hebreiska - hur får jag tillbaka den? Ingår den kanske också i samma funktion? Tacksam för hjälp!
- Pennan till vänster om "Avancerad"? Taylor 49 (diskussion) 21 april 2021 kl. 01.28 (CEST)
- Tack! Jag letade under inställningar, men det var alltså mycket lättare än så. Svenji (diskussion) 21 april 2021 kl. 01.50 (CEST)
Mall som hämtar från Wikidata
redigeraDet finns nu många estniska ord med böjningsformer som lexem i Wikidata. Kan vi få en mall/modul här som visar dem? Se t.ex päev (som saknar böjningsformer) och d:Lexeme:L381851 (som har dem). --LA2 (diskussion) 23 april 2021 kl. 00.52 (CEST)
- Frågan är nu även framlagd på en:Wiktionary:Grease pit/2021/April#Getting inflection tables from Wikidata. --LA2 (diskussion) 27 april 2021 kl. 19.41 (CEST)
Tyska mallar
redigeraSkulle tyska {{de-verb}} kunna utrustas med gröna länkar? Så att man lätt kan skapa böjningsformer för verb som tagen#Tyska och toppen#Tyska. Det är en vanlig mall (inte modul) som använder {{länk}}. Borde den göras om till modulkod? --LA2 (diskussion) 21 maj 2021 kl. 16.49 (CEST)
- Jag kan inte tyska, men det verkar som att artiklarna ställer till det för att det ska gå att använda den vanliga
{{länka-b}}mallen. @Skalman, kan du utveckla? Kanske att skapa en modul är enda möjligheten att komma till rätta med detta. Om en modul ska skapas vore det bra om ett helhetsgrepp togs för alla tyska verbmallar. Hur heltäckande och hur stabila är de tre befintliga verb-mallarna? Dodde (diskussion) 21 maj 2021 kl. 18.07 (CEST)
- Jag har uppdaterat
{{de-verb}}, så att gröna länkar skapas. Det är inte alldeles optimalt, då mallen tydligen inte har faktagranskats och man riskerar att potentiellt skapa upp felaktiga böjningsformer. Om man ändå vet att den böjningsformen stämmer, så blir det ju hur som helst smidigt att använda. Skalman (diskussion) 22 maj 2021 kl. 00.01 (CEST)- Jag snöade visst in på en redigeringskommentar från 2017 om länka-b-mallen, men nu har vi ju istället den mer uppdaterade
{{g-cell}}-mallen. Tack för att du fixade utbytet från{{länka}}till{{g-cell}}, Skalman. Jag började så smått med modultester för tyska verb (Modul:de-verb/test), men jag kom sedan på svårigheterna vi stötte på 2017 som framgår av Moduldiskussion:de-verb. Att för enkelhetens skull köra med{{g-cell}}tills vidare är nog ett bra val. ~ Dodde (diskussion) 22 maj 2021 kl. 00.34 (CEST)
- Jag snöade visst in på en redigeringskommentar från 2017 om länka-b-mallen, men nu har vi ju istället den mer uppdaterade
- Jag har uppdaterat
- Tack, detta var en stor förbättring! Jag vet inte alls om våra tyska mallar är heltäckande, men jag vet genom stickprov att bara ungefär hälften av våra tyska adjektiv och verb har en böjningsmall inlagd, så här finns mycket att göra. Nu har jag i alla fall skapat böjningsuppslag för tagen#Tyska. De gröna länkarna har blivit blå. --LA2 (diskussion) 22 maj 2021 kl. 00.45 (CEST)
Kort fråga
redigeraVarför får inte uppslaget ^^ automatiskt en kategori? Svenji (diskussion) 25 maj 2021 kl. 11.09 (CEST)
- @Svenji Det får den. Som framgår av Wiktionary:Mallar/ordklassmallar så hamnar sidor som använder mallen
{{tecken}}i Kategori:Tecken om inte en mer specifik teckenkategori anges som första argument. På sidan ^^ har "--" angivits som första argument och sidan har därför hamnat i Kategori:--, vilket så klart inte var avsiktligt. I vanliga ordklassmallar används första argumentet för att ange språkkod, eller "--" när uppslaget är tvärspråkligt. Men tecken är redan tvärspråkliga, så därför saknas språkargument i tecken-mallen. ~ Dodde (diskussion) 25 maj 2021 kl. 13.52 (CEST)
Bugg i "MediaWiki:Common.css"
redigera- sv.wiktionary.org inkluderar massor av mallar och fastnar i 2 kategorier
- en.wiktionary.org inkluderar inga mallar
- @Taylor 49, jag fixade så att sidan inte fastnar i några kategorier. Däremot är det väl okej att inkludera mallar, så jag ändrar inte det. Ok? Skalman (diskussion) 11 augusti 2021 kl. 23.11 (CEST)
- @Skalman: Hej
== {{saknad betydelse|ejkat=}} ==
- Men varför inkluderas de överhuvudtaget? Är omnämningen i CSS-koden inte bara kommentar? Skulle sådant funka (och vara säkrare för alla mallar):
== { {saknad betydelse} } ==
- eller
/* <!--
== {{saknad betydelse}} ==
--> */
- eller (väl bäst, längst uppe och längst nere):
/* <nowiki> */
/* </nowiki> */
- Jag gillar att man ser länken till den när man kollar på "Vad som länkar hit". Om någon av mallarna skulle raderas i framtiden, blir det på så vis också uppenbart att CSS:en bör ändras. Men jag kan ändra till
[[Mall:saknad betydelse]]istället. Skalman (diskussion) 12 augusti 2021 kl. 11.10 (CEST)
- Jag gillar att man ser länken till den när man kollar på "Vad som länkar hit". Om någon av mallarna skulle raderas i framtiden, blir det på så vis också uppenbart att CSS:en bör ändras. Men jag kan ändra till
- @Taylor 49, en bättre lösning emm är om mallarna är så pass smarta att dom aldrig placerar sidan i en kategori om det inte är i huvudnamnrymden. Skalman (diskussion) 12 augusti 2021 kl. 11.19 (CEST)
- @Skalman: Kategorisering enligt namnrymd är en möjlighet som är lätt att implementera, men har nackdelen att den underminerar nyttan av sandlådan och privata sandlådor på undersidor av ens användarsida. Ifall du vill ha länkar kvar (vilket låter rimligt), då är
/* <nowiki> */den näst bästa lösningen, och[[Mall:saknad betydelse]]den bästa, då föreslår jag att ändra{{...}}till[[Mall:...]]. Taylor 49 (diskussion) 13 augusti 2021 kl. 22.10 (CEST)
- @Skalman: Kategorisering enligt namnrymd är en möjlighet som är lätt att implementera, men har nackdelen att den underminerar nyttan av sandlådan och privata sandlådor på undersidor av ens användarsida. Ifall du vill ha länkar kvar (vilket låter rimligt), då är
Bugg: ".WAV"-filer spelas inte utan laddas ner
redigera- arbetslöshet "Sv-arbetslöshet.ogg" -> funkar
- xenon "LL-Q9027 (swe)-Moonhouse-xenon.wav" -> laddas ner
Jag vet inte vad det beror på men det funkar vid -eo- wiktionary. Taylor 49 (diskussion) 3 augusti 2021 kl. 00.22 (CEST)
- Skillnaden är väl att eo använder en speciell mall som ger en integrerad ljudspelare direkt på sidan, medan sv inte gör det, utan bara länkar till filen. Om du låter din webbläsare göra en HTTP GET-förfrågan på själva WAV-filen på eo ser du att den laddas ner även där. För att pröva det, klicka på länken på [1]. (Det har kanske med serverns MIME-typer att göra?) Men om du på sv klickar på högtalarikonen så kommer du till filsidan där du får en inbäddad spelare. --Andreas Rejbrand (diskussion) 3 augusti 2021 kl. 00.44 (CEST)
Bugg: "$wgExpensiveParserFunctionLimit" för lyxiga funktioner
redigeraDet här är en förargelse och bråkmakare som ställer till det vid många wikier. Strängt taget är det inte en bugg utan en feature som lades till för länge sedan. Gränsen är för närvarande 500 anrop och gäller främst (summan av) ifexists and pagesincategory men ej transkluderingar vilket är märkligt (se nedan). Försök att få igenom en höjning för antingen en wiki eller alla WMF wikier är dömda att få T160685 avslag av "principiella skäl". Vi har ca 420 språkkoder varav ca 360 har uppslag. Vid 500 kategorier med uppslag kommer antalet huvuduppslag på titelsidan att sluta funka eftersom detta beräknas medelst pagesincategory. Vi har råd med ett anrop till en kostsam (lyxig, resurskrävande) funktion per språk, men inte mer. Detta begränsar möjligheter till listor över språk och statistik. Liknande problem finns vid andra wiktionaryer. Det finns ytterligare begränsningar såsom RAM-minne som -en- wiktionary ville ha en höjning på T165935 men fick avslag. Nu håller de på med desperata förändringar som försämrar kvaliteten men kanske reducerar minnesförbrukningen lite grann. Jag har tre ideer att få bukt med det här, som inte kan avslås av "principiella skäl" eftersom de alla är resursneutrala.
- T278629 Omförhandla prislistan och gör transklusioner dyrare och ifexists and pagesincategory billigare. Det är orimigt att transklusioner som uppenbarligen är mycket mer resurskrävande är gratis medan ifexists kostar. Jag har även utvecklat ett knep som exploaterar den här absurditeten (Provujo länkat från "phabricator") och verkställer 676 ifexists-begäran med giltiga resultat och utan någon skampålekategori. Tyvärr funkar knepet inte för pagesincategory.
- Batcha sådana begäran. Enligt svaret går det internt att batcha ifexists-begäran, och således bör detta göras tillgångligt även från LUA. Jag vet inte ifall detta gäller också för pagesincategory.
- Höjning mot restriktioner. Ingen bugg-item vid "phabricator" ännu. Skapa en ny "content model" kallad för "privileged wikitext" som funkar på samma sätt som "wikitext" med följande 3 avvikelser:
- Kraftigt höjda begränsningar, till exempel 500->10'000 lyxiga funktioner, 10s->40s LUA-tid, 50MiO->200MiO RAM, 2MiO->8MiO pre-expand&post-expand bloat.
- mot
- Sidan kan redigeras enbart av administratörer.
- Sidan kan uppdateras enbart sällan, till exempel 1 gång per timme och 3 gånger per dygn, plus mindre ofta eller inte alls automatiskt.
- Kraftigt höjda begränsningar, till exempel 500->10'000 lyxiga funktioner, 10s->40s LUA-tid, 50MiO->200MiO RAM, 2MiO->8MiO pre-expand&post-expand bloat.
Finns det åsikter kring detta? Jag ber om stödjande röster på min bugg T278629 (batcha allt som går att batcha). Taylor 49 (diskussion) 3 augusti 2021 kl. 01.31 (CEST)
- Jag har lagt till en notis till din appell på Phabricator om att jag stödjer ditt förslag. –Tommy Kronkvist (diskussion), 9 augusti 2021 kl. 15.38 (CEST).
- Jag håller med om att dessa funktioner nog behöver ses över. Mest realistiskt skulle jag tro är Lua-funktioner som stödjer batchning av ifexists och pagesincategory.
- En fullösning för huvudsidan skulle vara att helt sonika exkludera dom minsta språken (eller lägga till en hårdkodad schablonsumma för dom).
- @Taylor 49, har du något exempel utöver huvudsidan som ger problem på sv-wikt? Skalman (diskussion) 11 augusti 2021 kl. 23.54 (CEST)
- @Skalman: Jo, batchning av ifexists och pagesincategory vore bäst. Problemsidor: Wiktionary:Alla språk och koder med antal huvuduppslag -- för att evaluera hur många kategorier som saknas skulle det behövas min hack. Wiktionary:Balans efter språk och ordklass Och aldono. PS:
{{antal uppslag}}har parametrar "list=" , "omit=" och "limit=" som kan användas i ett desperat läge. PPSS: finns det kanske en bättre lösning för MediaWiki:Common.css, se ovan? Taylor 49 (diskussion) 12 augusti 2021 kl. 00.07 (CEST)- Hur ser de andra språkversionerna av Wiktionary på det här? De torde ju vara uppbyggda på liknande sätt (?) och snart komma att uppleva samma problem som vi. –Tommy Kronkvist (diskussion) 12 augusti 2021 kl. 18.53 (CEST), 12 augusti 2021 kl. 18.53 (CEST).
- Se ovan, de har redan problem. Det gäller bara att ta kontakt. Wiktionary:Bybrunnen/Arkiv26#Modul_önskas_för_beräkningsmall. 16 augusti 2021 kl. 15.49 (CEST)
- Hur ser de andra språkversionerna av Wiktionary på det här? De torde ju vara uppbyggda på liknande sätt (?) och snart komma att uppleva samma problem som vi. –Tommy Kronkvist (diskussion) 12 augusti 2021 kl. 18.53 (CEST), 12 augusti 2021 kl. 18.53 (CEST).
- @Skalman: Jo, batchning av ifexists och pagesincategory vore bäst. Problemsidor: Wiktionary:Alla språk och koder med antal huvuduppslag -- för att evaluera hur många kategorier som saknas skulle det behövas min hack. Wiktionary:Balans efter språk och ordklass Och aldono. PS:
Färger
redigeraÄr det bara jag som inbillar mig, eller har färgerna på hyperlänkar ändrats (om än ytterst subtilt)? --Andreas Rejbrand (diskussion) 13 augusti 2021 kl. 15.39 (CEST)
- Du ser alltid saker som knappast syns (såsom buggen ovan med minimalt felplacerad text i tabellerna) och ingen annan skulle våga påtala. ;-) Taylor 49 (diskussion) 13 augusti 2021 kl. 22.14 (CEST)
- Jo, visst har de väl blivit lite ljusare? Svenji (diskussion) 16 augusti 2021 kl. 11.29 (CEST)
- Aningen ljusare, upplever jag det som. Synd att sidor som till exempel w:Wikipedia:Länkfärg (eller motsvarande på enWP, Meta-Wiki etc.) inte länkar direkt till någon "global" Wikimedia-CSS eller liknande, så att man enkelt skulle kunna titta efter i historiken. –Tommy Kronkvist (diskussion), 17 augusti 2021 kl. 00.24 (CEST).
- Jag ser ingen skillnad, men jag har heller inte en skärm som återger färger jättebra. Men inte heller i koden ser jag några indikationer på att länkfärgen ska ha ändrats dom senaste 10 åren. Däremot kan det ju vara så att färgen har överridits, men inte längre gör det, så helt säker på vad som hänt i koden är jag inte.
- Detta är den relevanta CSS-koden som körs på min dator: https://gerrit.wikimedia.org/r/plugins/gitiles/mediawiki/core/+blame/refs/tags/1.36.1/resources/src/mediawiki.skinning/elements.less#14
- Annat som potentiellt skulle kunna påverka, men som inte heller verkar så sannolikt: typsnittet har ändrats, webbläsarens tolkning av färg+typsnitt har förändrats, webbläsarens standardtypsnitt (vilket är det som Vector verkar använda som standard) har förändrats, operativsystemets tolkning av typsnitt har förändrats... Skalman (diskussion) 17 augusti 2021 kl. 10.58 (CEST)
- Jo, det har blivit ljusare. Speciellt tydligt ser jag det på röda länkar, som här. Något har hänt, men i vilket fall som helst så har jag inga problem med ändringen. --Andreas Rejbrand (diskussion) 17 augusti 2021 kl. 13.48 (CEST)
- Här syns skillnaden tydligt: https://privat.rejbrand.se/wtlinkcolour.png. Överst är en äldre skärmdump från januari 2017; underst är från i dag. --Andreas Rejbrand (diskussion) 17 augusti 2021 kl. 13.55 (CEST)
{kind=link}
- Jag trodde att det var något som hade hänt dom senaste dagarna, och jag trodde att det gällde andra länkar än rödlänkar. Om jag förstår rätt, så är den aktuella ändringen från mars 2021 och borde ha deployats ganska snart efter det (inom en månad, tror jag). Skalman (diskussion) 17 augusti 2021 kl. 16.22 (CEST)
- Jag är helt säker på att färgerna på min dator ändrades samma dag som jag skrev inlägget ovan! --Andreas Rejbrand (diskussion) 17 augusti 2021 kl. 17.57 (CEST)
- I så fall har jag kanske fel vad gäller inom en månad från mars 2021. Deploy av nya versioner kanske fungerar annorlunda än vad jag minns det som. Skalman (diskussion) 17 augusti 2021 kl. 19.20 (CEST)
"Mall:kategorinavigering-härledningar" - modularisering
redigeraJag har just modulariserat denna mall. Mall:kategorinavigering-härledningar Fördelar:
- parametrar behövs ej längre:
Det andra språket anges här med versalinitial (på Svenska/Härledningar från fornsvenska anges Fornsvenska) - språkkoder visas
- alla tänkbara fel detekteras och bestraffas med felmeddelande liksom spårningskategori
- etymologiska koder uppmärksammas (se Kategori:Svenska/Härledningar från samiska) och funkar enbart efter
Härledningar från, motsatt "Kategori:Samiska/Härledningar från svenska" skulle ej funka
Jag föreslår att ta bort parametrarna medelst bot på alla sidor som använder mallen (kan det röra sig om enbart 487 ??). Taylor 49 (diskussion) 23 augusti 2021 kl. 00.44 (CEST)
- @Taylor 49: Trevligt att bli av med parametrarna! Några kommentarer:
- Varför behöver språkkoderna visas?
- Nu genereras ett stycke
<p>som innehåller två<br><br>. Skulle det gå att istället generera två<p>? - Jag skulle föredra aningen tydligare variabelnamn i modulen, och skulle kanske ha döpt modulen till samma sak som mallen (eftersom den bara används där), men det är småsaker som spelar mindre roll. :-)
- Skalman (diskussion) 23 augusti 2021 kl. 09.50 (CEST)
- > varför behöver språkkoderna visas
- eftersom de behövs då en skapar nya uppslag (en kod) eller lägger till härledning (två koder)
- vänta ... "fornindonesiska" ... vilken kod hade den igen ... var hade vi listan ... jag kan inte hitta den längre ... jävlar ...
- jag har dåliga erfarenheter med vissa wikier som skryter med språknamn men vill ha koder som inmatning
- och dessutom vill jag ha en nytta för funktion "getCode" ... ;-)
- > det gå att istället generera två
- Det går säkert ... hur menar du det exakt, och vad ska vara fördelen?
- Taylor 49 (diskussion) 23 augusti 2021 kl. 14.20 (CEST)
- > varför behöver språkkoderna visas
- @Taylor 49:
- Språkkoder: Jo, du har rätt i att det finns en poäng i att visa språkkoden. Jag skulle föredra en lite annan formatering, men är inte alldeles säker på vad jag tycker skulle bli snyggast. Kanske (kod xx)? Jag har inte jättestarka preferenser här, men tycker att det ser konstigt ut med bindestrecken.
- <p>: Huvudfördelen är att det ser bättre ut när det inte är så stort avstånd mellan raderna. Generellt bör du undvika <br> och istället använda antingen radbrytningar,
<p>Textrad</p>eller<div>Textrad</div>.
- Skalman (diskussion) 24 augusti 2021 kl. 20.35 (CEST)
- @Taylor 49:
- Jag har tagit bort dessa
<br>(British Rail) och ersatt dem med<div>(Divison). Avståndet har blivit lite mindre. Taylor 49 (diskussion) 2 september 2021 kl. 17.22 (CEST)
- Jag har tagit bort dessa
- Boten ska avfiras nu. Taylor 49 (diskussion) 4 september 2021 kl. 21.18 (CEST)
- ✔ Parametrarna har tagits bort från alla anrop, och omedelbart därefter förbjudits i modulkoden. Taylor 49 (diskussion) 4 september 2021 kl. 22.38 (CEST)
- Applåd och lyft på hatt! Tommy Kronkvist (diskussion), 5 september 2021 kl. 03.35 (CEST).
- ✔ Parametrarna har tagits bort från alla anrop, och omedelbart därefter förbjudits i modulkoden. Taylor 49 (diskussion) 4 september 2021 kl. 22.38 (CEST)
- Boten ska avfiras nu. Taylor 49 (diskussion) 4 september 2021 kl. 21.18 (CEST)
Översättningar läggs in fel i listor som har en dubbel asterisk
redigeraVarför läggs översättningar till i oordning? Jag trodde detta var en historisk bugg, men den är livs levande i dag. Här, till exempel, lades "albanska" inte först i listan (som förhandsvisningen angav), utan efter dubbelstjärnan för högsorbiska. --LA2 (diskussion) 8 oktober 2021 kl. 17.21 (CEST)
- Pga en bugg här: MediaWiki:Gadget-translation editor.js. Kan reproducera problemet. Enbart @Skalman kan fixa den här buggen. Taylor 49 (diskussion) 10 oktober 2021 kl. 02.03 (CEST)
- På rad 682 är en loop som stegar bakifrån igenom en lista. Det låter som felets orsak. Om man stegar bakifrån och hittar "**", så är ju det elementet mindre än aktuella språket och alltså stannar man och sätter in där. Koden borde stega uppifrån i listan tills den hittar ett större värde än det aktuella, för då kommer den aldrig att stanna vid "**". --LA2 (diskussion) 10 oktober 2021 kl. 03.31 (CEST)
- Tack för tipset på en bättre algoritm. Det fanns troligen en anledning att göra som jag gjorde, men idag förstår jag inte vad det skulle kunna vara
 . Jag har också fixat en bugg med förhandsvisningen av tillagda översättningar. Det hela ska fungera nu. Skalman (diskussion) 12 oktober 2021 kl. 00.59 (CEST)
. Jag har också fixat en bugg med förhandsvisningen av tillagda översättningar. Det hela ska fungera nu. Skalman (diskussion) 12 oktober 2021 kl. 00.59 (CEST)
- Tack, verkar fungera bra! --LA2 (diskussion) 12 oktober 2021 kl. 16.10 (CEST)
- Tack för tipset på en bättre algoritm. Det fanns troligen en anledning att göra som jag gjorde, men idag förstår jag inte vad det skulle kunna vara
- På rad 682 är en loop som stegar bakifrån igenom en lista. Det låter som felets orsak. Om man stegar bakifrån och hittar "**", så är ju det elementet mindre än aktuella språket och alltså stannar man och sätter in där. Koden borde stega uppifrån i listan tills den hittar ett större värde än det aktuella, för då kommer den aldrig att stanna vid "**". --LA2 (diskussion) 10 oktober 2021 kl. 03.31 (CEST)
Turkiska Wiktionary har samma problem i kvadrat. Exempel: 1, 2, 3, 4. Vår MediaWiki:Gadget-translation editor.js motsvaras av deras tr:MediaWiki:Gadget-CeviriEkleyici.js (çeviri = översättning, ekle = lägg till) eller kanske tr:MediaWiki:Gadget-CeviriEkleyici-Veri.js. Men felet tycks bestå i att sorteringen sker i Unicode-ordning (Ç efter Z) i stället för enligt turkisk kollationsordning (Ç som C). Och var i programmet ligger det? Kanske handlar det om någon global parameter, snarare än den här koden? (@Skalman, @Taylor 49) --LA2 (diskussion) 29 oktober 2021 kl. 19.02 (CEST)
- Är problemet nu fixat (hos oss) eller inte? Taylor 49 (diskussion) 29 oktober 2021 kl. 23.03 (CEST)
- Jag tror det är löst hos oss. --LA2 (diskussion) 30 oktober 2021 kl. 18.18 (CEST)
- Ganska komplicerat. Du har nog rätt i att den försöker sortera i Unicode-ordning. Jag tror att jämförelserna här inte sorterar korrekt:
// Rad 1095
} else if (ln && ln > lang && (!nextLanguage || ln < nextLanguage) && lis[j].parentNode.parentNode.nodeName != 'LI') {
// Rad 1224
} else if (ln && ln > nestedHeading && (!nextLanguage || ln < nextLanguage)) {
- Men jag är inte alls säker på att detta är dom enda ställena.
- Vi har faktiskt samma problem på svwikt, även om det uppträder mycket mer sällan: (italienska, iñupiaq) och (žemaitiska, zhuang) sorteras fel. Om "õ" ska sorteras som "o", så är också (võro, votiska) fel (men iaf sv-wp sorterar det som "ö", vilket i så fall betyder att det är rätt). Skalman (diskussion) 31 oktober 2021 kl. 14.56 (CET)
- Så vitt jag ser, anger javascript-koden ingenstans vilken sorteringsordning som ska gälla. Alltså går den på någon sorts default, och sådant är ju alltid lite osäkert. Hur skulle man kunna implementera detta på ett stabilt sätt, utan att vara beroende av sorteringsordningen? Kunde man följa listan över godkända språkkoder i stället för att strängjämföra språknamnen? Jag är inte hemma i Javascript, men i Perl skulle man kunna lägga in alla översättningar i en hash-tabell och sedan skriva ut hela hash-tabellen i den ordning som anges av en array (no, bg, da) som gör att ordningen alltid blir Bokmål, Bulgariska, Danska. --LA2 (diskussion) 1 november 2021 kl. 19.00 (CET)
- Enligt Stack Overflow finns en String.prototype.localeCompare som man bör använda. Och här är kod hos oss som använder localeCompare på strängar: MediaWiki:Gadget-unit tests/qunit.js. --LA2 (diskussion) 1 november 2021 kl. 20.02 (CET)
- Default är unicode, så det är inte "osäkert" men nog inte det vi önskar.
- Lättast är att använda
localeCompare, som skulle sortera võro före votiska. Är detta acceptabelt? - Om man vill följa den ordning som finns på Modul:lang/data, måste man ladda in samtliga språk, vilket känns lite onödigt. Men det är också en möjlig lösning. Skalman (diskussion) 1 november 2021 kl. 23.36 (CET)
- Enligt Stack Overflow finns en String.prototype.localeCompare som man bör använda. Och här är kod hos oss som använder localeCompare på strängar: MediaWiki:Gadget-unit tests/qunit.js. --LA2 (diskussion) 1 november 2021 kl. 20.02 (CET)
- Säger svensk locale verkligen att õ ska sorteras som o? Tecknet används väl nästan bara som estniskt ö (som just i võru) och borde sorteras som ö och ø, tycker jag. --LA2 (diskussion) 2 november 2021 kl. 00.24 (CET)
- Ja, tyvärr. Inte heller våra egna
sort_rulespå Modul:lang/data eller infon på Appendix:Alfabet#Svenska tar hänsyn till õ, kanske eftersom det sorteras som (eller efter) o på vissa språk. Samma problem finns alltid när man måste känna till ursprungsspråket för att veta hur det ska sorteras. - Vilken väg tycker du att vi ska gå? Skalman (diskussion) 2 november 2021 kl. 00.49 (CET)
- Ja, tyvärr. Inte heller våra egna
- Säger svensk locale verkligen att õ ska sorteras som o? Tecknet används väl nästan bara som estniskt ö (som just i võru) och borde sorteras som ö och ø, tycker jag. --LA2 (diskussion) 2 november 2021 kl. 00.24 (CET)
- För mig är võru av så marginell betydelse, att jag inte bryr mig. Viktigare för mig är att få tr.wiktionary att fungera, och det hänger på att hitta en admin med rättigheter och vilja att debugga koden. Men rätt metod borde vara att överallt använda localeCompare, och sedan hoppas att svensk locale förbättras någon gång i framtiden. --LA2 (diskussion) 2 november 2021 kl. 01.36 (CET)
- Jag har fixat sv-wikts sorteringsordning, så om någon wikt kopierar vår kod, bör sorteringen bli rätt.
- Jag skulle kunna kika/experimentera med tr-wikts översättningsskript, men om jag inte lyckas lösa det på en timme, så kommer jag ge upp. Det skulle kräva att jag får gränssnittsadminbehörighet. Skalman (diskussion) 3 november 2021 kl. 23.38 (CET)
- För mig är võru av så marginell betydelse, att jag inte bryr mig. Viktigare för mig är att få tr.wiktionary att fungera, och det hänger på att hitta en admin med rättigheter och vilja att debugga koden. Men rätt metod borde vara att överallt använda localeCompare, och sedan hoppas att svensk locale förbättras någon gång i framtiden. --LA2 (diskussion) 2 november 2021 kl. 01.36 (CET)
- Användaren HastaLaVi2, som talar turkiska och har rättigheter, men kanske inte är jättehaj på Javascript, har i dag försökt fixa buggen i tr:MediaWiki:Gadget-CeviriEkleyici.js, men rodde inte båten i land och återställde till gamla versionen. Kan du kolla ändringarna mellan de senaste versionerna och kanske komma med kommentarer och idéer? Användaren har också laborerat med en egen kopia, tr:User:HastaLaVi2/Gadget-CeviriEkleyici.js. --LA2 (diskussion) 4 november 2021 kl. 21.19 (CET)
- Jag har fixat något som verkar funka skapligt: tr:User:Skalman/common.js som ersätter tr:MediaWiki:Gadget-CeviriEkleyici.js.
- Funkar: sparar konsekvent saker i rätt ordning
- Funkar inte (men likadant som idag): om man lägger till ett språk som ska hamna efter resterande, så visas detta som en del av en helt ny lista (istället för att bäddas in i den existerande)
- Inte testat: underspråk (dubbla asterisker)
- Jag tror alltså att det här här värt att lägga in, eftersom det viktiga väl är hur det sparas. Skalman (diskussion) 5 november 2021 kl. 19.18 (CET)
- Jag har fixat något som verkar funka skapligt: tr:User:Skalman/common.js som ersätter tr:MediaWiki:Gadget-CeviriEkleyici.js.
- Användaren HastaLaVi2, som talar turkiska och har rättigheter, men kanske inte är jättehaj på Javascript, har i dag försökt fixa buggen i tr:MediaWiki:Gadget-CeviriEkleyici.js, men rodde inte båten i land och återställde till gamla versionen. Kan du kolla ändringarna mellan de senaste versionerna och kanske komma med kommentarer och idéer? Användaren har också laborerat med en egen kopia, tr:User:HastaLaVi2/Gadget-CeviriEkleyici.js. --LA2 (diskussion) 4 november 2021 kl. 21.19 (CET)
- Så om varje lista redan hade ett element för Zulu (eller vilket språk som sorterar sist i alfabetet), så skulle det fungera bättre? Jag ser att du skickar med 'tr' som andra parameter till localeCompare(). Är det nödvändigt? Följer det inte med sajten som default? --LA2 (diskussion) 5 november 2021 kl. 19.51 (CET)
- Ja, om listan hade Zulu skulle det alltid funka. Men det är inte förvirrande nu heller, bara konstigt.
- 'tr' är nödvändigt att skicka in. Annars får man en "internationell" sortering. Skalman (diskussion) 5 november 2021 kl. 21.53 (CET)
- Så om varje lista redan hade ett element för Zulu (eller vilket språk som sorterar sist i alfabetet), så skulle det fungera bättre? Jag ser att du skickar med 'tr' som andra parameter till localeCompare(). Är det nödvändigt? Följer det inte med sajten som default? --LA2 (diskussion) 5 november 2021 kl. 19.51 (CET)
- Jag ser att svenska koden skickar med 'sv'. Men är det inte lite konstigt att det ska behövas? Borde inte respektive sajt köra med egna språket som default? --LA2 (diskussion) 6 november 2021 kl. 00.00 (CET)
- Nej, det är inte konstigt. I html är det specat att
lang="sv", men detta slår inte över till Javascript. Man kan göra jämförelserna utan att upprepa språkkoden, men vi gör jämförelserna på så få ställen att det inte blir värt det. Historiskt har Javascript-api:erna bara använt webbläsarens språk, medan api:er från det här århundradet (tack och lov!) har varit "tvärspråkliga" (något som liknar det man skulle skriva i kod). Skalman (diskussion) 6 november 2021 kl. 21.26 (CET)
- Nej, det är inte konstigt. I html är det specat att
- Jag ser att svenska koden skickar med 'sv'. Men är det inte lite konstigt att det ska behövas? Borde inte respektive sajt köra med egna språket som default? --LA2 (diskussion) 6 november 2021 kl. 00.00 (CET)
Ett stort framsteg har skett. Man kan nu lägga till cs (Çekçe) och det sorteras in korrekt före Danca (danska). Men zh (kinesiska, Çince) kommer fortfarande sist i listan. Se diskussionen här och exemplet tr:pazarlama (dess historik). --LA2 (diskussion) 6 november 2021 kl. 22.53 (CET)
Redskap
redigeraOm nu översättningar har lagts in i fel ordning, och vi misstänker att det kan ha pågått länge, har vi då något verktyg (en bot) för att kontrollera att ordningen nu är den rätta, eller hitta de artiklar där ordningen är fel? --LA2 (diskussion) 10 november 2021 kl. 17.05 (CET)
Babel-mallen
redigeraHej! Vart går jag för att göra en liten ändring i babel-mallarna för jiddisch? För närvarande återger inte mallen på sv.wikt de diakritiska tecknena till alef, yud och fey, det vill säga nuvarande texten "דער באניצער האט א גרונטיקע ידיעה אין יידיש" skulle ändras till "דער באַניצער האָט אַ גרונדיקע ידיעה אין ייִדיש" (der banitser hot a grundike yedie in yidish). Engelska Wiktionary har f.ö. en helt annan text: ".דער באַניצער האָט תּוך־ידיעה פֿון ייִדיש." (der banitser hot tokh-yedie fun yidish." Svenji (diskussion) 10 oktober 2021 kl. 20.36 (CEST)
- Jag vet inte, men gissar att https://sv.wiktionary.org/wiki/Special:Systemmeddelanden?prefix=babel&filter=all&lang=yi är ett ställe att börja leta på. Eftersom mallen babel anropar "parserfunktionen" (intern kod) #babel, så bör det vara ett systemmeddelande. Men de bör väl vara lika för alla wiki-sajter. Får du rätt accenter på engelska Wiktionary eller på svenska Wikipedia? --LA2 (diskussion) 11 oktober 2021 kl. 00.25 (CEST)
- Svenska Wikipedia har en tredje variant (!): "דער באַניצער קען ביישטייערן מיט אַ גרונטלעכער דרגה פון ייִדיש.", .der banitser ken beyshteyern a gruntlekher dreyge (från hebreiska = "nivå, grad", translitteration?) fun yidish", där även punkten hamnar fel (ska stå till vänster). Svenji (diskussion) 17 januari 2022 kl. 16.20 (CET)
Rohingisk (rhg)
redigera(Can somebody translate this post, please?)
The translation-adding feature ({{ö-topp}} & {{ö-botten}}) doesn't have the language code "rhg" for the Rohingya language. --Apisite (diskussion) 14 november 2021 kl. 12.32 (CET)
(@LA2 What do you think?) --Apisite (diskussion) 14 november 2021 kl. 13.48 (CET)
- Användare:Skalman typically handles these kinds of requests. I am sure Skalman or some other technician will handle your request later today or within a few days. --Andreas Rejbrand (diskussion) 14 november 2021 kl. 14.14 (CET)
- A beginning might be to create an entry in Modul:lang/data. But what is the language called in Swedish? The Wikipedia article w:Rohingyer (about the people, Wiktionary: rohingyer) states that the language is called ruáingga (which doesn't have an article). --LA2 (diskussion) 14 november 2021 kl. 17.15 (CET)
- @LA2, @Skalman - Maybe either Rohingisk or Rohingyask. --Apisite (diskussion) 14 november 2021 kl. 17.22 (CET)
- I can't find any texts in Swedish that talk about the language. Apparently, it is not a topic of discussion. German Wikipedia has an article about the people, that also discusses "their language", but avoids to give the language any name. Perhaps "ruáingga" is correct in some sense, but since the topic is so remote to Swedish readers I think any term other than "rohingya" will have problems. I suggest we call the language "rohingya". (Languages are lowercase in Swedish.) --LA2 (diskussion) 14 november 2021 kl. 18.19 (CET)
- @LA2, @Skalman - ✔ Added "rhg" to Modul:lang/data. --Apisite (diskussion) 14 november 2021 kl. 19.00 (CET)
- @Apisite, it seems like you already added support at Modul:lang/data, which is all that's needed to make it work in translations. In addition, I've added the language to our documentation and to another script. Skalman (diskussion) 14 november 2021 kl. 21.18 (CET)
- It seems like I was responding to a very old version of this discussion. Skalman (diskussion) 14 november 2021 kl. 21.26 (CET)
- It seems like I was responding to a very old version of this discussion.
- @Apisite, it seems like you already added support at Modul:lang/data, which is all that's needed to make it work in translations. In addition, I've added the language to our documentation and to another script. Skalman (diskussion) 14 november 2021 kl. 21.18 (CET)
Language code tsg
redigera@LA2, @Skalman What language name could be used for the language code tsg, "sulu", "suluk" or "tausug"? --Apisite (diskussion) 25 november 2021 kl. 06.45 (CET)
- @Apisite, it seems like NE uses tausug, so that's what I'd go with. Skalman (diskussion) 25 november 2021 kl. 11.23 (CET)
- @LA2, @Skalman - ✔ I have added not only Tausug (tsg), but also Magindanaw (mdh) and Maranao (mrw). --Apisite (diskussion) 25 november 2021 kl. 17.05 (CET)
- @LA2, @Skalman I have added also Yakan (yka) to Modul:lang/data. --Apisite (diskussion) 25 november 2021 kl. 17.44 (CET)
- @Svenji Svenji, I see that you've likely seen this thread. --Apisite (diskussion) 25 november 2021 kl. 17.49 (CET)
- I guess this is good. I have no reason to believe otherwise. But it is frustrating to know that it might be years before anybody joins the Swedish Wiktionary user community with any insights that might correct any wrongs about these languages, which are so remote to the Swedish user base. It is also long before the same level of support will be added to smaller and less active Wiktionary sites, such as the Danish or Turkish Wiktionary. Much of this basic support should be made a global part of Wiktionary, and not added to each separate version. --LA2 (diskussion) 25 november 2021 kl. 21.27 (CET)
- @Apisite - thank you, and yes. I see that the language called Magindanaw in English has an entry on NE as magindanao. That follows Swedish orthography better, so I would more recommend that to be the name we use here. About the Yakan language, my gut feeling would be that it's spelt jakan in Swedish, just like Yakut is jakutiska, Yiddish is jiddisch, and so forth. However, I could not find anything to support previous Swedish mention of the language. Svenji (diskussion) 25 november 2021 kl. 21.30 (CET)
- I'm all for language plurality and inclusion, but perhaps with a limit. I encouraged the creation of at least 500 entries in each of the 24 official languages of the European Union, which is why we now have 500 entries in Maltese. But I'm less optimstic about Bavarian (Kategori:Bayerska), South Sami (Kategori:Sydsamiska), and other tiny languages (Bavaria is not small, but most people there only write in standard German, not in the Bavarian dialect). The same goes with languages that are large but very remote and have very little interchange with Swedish. Is it likely that any native speaker of Rohingya will become a contributor to Swedish Wiktionary? Sweden has many thousands of Arabic- and Somali-speaking immigrants, but none or very few come to Wiktionary. Most immigrants focus on learning Swedish, not to learn and teach Arabic (Kategori:Arabiska) or Somali (Kategori:Somaliska). We still only have 259 entries in Arabic. --LA2 (diskussion) 25 november 2021 kl. 23.52 (CET)
- From a linguistic point of view, I find every language - however small - to join the project interesting. The issue is of course the problem of fact-checking these words, without knowledge or proper dictionaries at hand. I don't see why Southern Sami would be problematic, as being a vital language in Sweden and one variety of Sweden's official minority languages. More people speak Southern Sami in Sweden than Yiddish, but the latter being a language with big literal history and with speakers living in all corners of the world. When it comes to the Swedish project, I share the concern about major immigrant languages, such as Arabic, Somali, Persian and Thai are so small here still. My wish is that we get a bilingual editor of these languages to help out ASAP. I'm very happy for your recent contributions with Turkish, @LA2. With template structures available, it could easily spark more contributors interest in adding more data. Hopefully I will learn to read the abjad for Farsi next year or so, and then get my head around this meta-language so we get a bit better coverage. At the moment my focus has to stay with my studies in Spanish and Yiddish. And while I'm at it, I really appreciate the Indonesian contributions from you, @Taylor 49. I would love to see Malay grow on here too. Svenji (diskussion) 26 november 2021 kl. 01.00 (CET)
Two More Languages
redigera@LA2, @Skalman, @Svenji: I would like to have two (2) more languages, Ternate (tft) and Tidore (tvo), to Modul:lang/data added. --Apisite (diskussion) 27 november 2021 kl. 02.55 (CET)
CSS-bugg i böjningsmall för substantiv
redigeraTitta på böjningstabellen i artikeln täckdag. I kolumnen för plural bestämd form genitiv är texten flera pixlar upphöjd. --Andreas Rejbrand (diskussion) 12 december 2021 kl. 17.10 (CET)
Trasig latin-mall
redigeraMallen {{la-subst-3-n}} visar inte böjningar, utan bara tomma fält. Svenji (diskussion) 18 mars 2022 kl. 22.49 (CET)
Grönlänkar till sidor som finns
redigeraDet är ytterst bekvämt att utifrån en lista med översättningar kunna klicka en grön länk och därmed skapa nya sidor och uppslag. Jag lade nyss till flera översättningar till ordet bar (utskänkningsställe) och klickade sedan på kyrilliska бар och skapade sidan med många uppslagsord på en gång. Men jag kan inte klicka på spanska översättningen "bar", för den sidan finns redan och länken är blå, inte grön. Skulle det vara möjligt att krångla till koden så att länken för spanska bar blir grön och nya uppslag skapas i den befintliga sidan? --LA2 (diskussion) 21 mars 2022 kl. 17.24 (CET)
- @Användare:LA2: Jag tror inte. Detta skulle kräva att JawaScript läser hela denna sida ("bar" i det här fallet) och kollar ifall språket (spanska i det här fallet) redan finns. Visst skulle den kunna avbryta sökningen vid "Swahili" förutsatt att språken är sorterade. Detta skulle behöva göras för alla översättningar, dvs ifall det finns 100 språk med totalt 200 länkade ord, då skulle JawaScript behöva läsa och analysera upp till 200 sidor, bara för att avgöra "blått piller eller grönt piller". Alternativt skulle den kunna kolla ifall sidan i fråga är i kategorin (Kategori:Spanska/Alla uppslag i det här fallet) vilket väl är bättre, men ändå skulle behöva göras för alla länkade ord, i översättningar och böjningstabeller. Plus risken att sidan visserligen har språket men med fel ordklass. Men det är Användare:Skalman som är auktoriteten på JawaScript. Taylor 49 (diskussion) 24 mars 2022 kl. 09.45 (CET)
- Att det går snabbt att kolla om sidan finns, beror ju på att det finns en databastabell över sidor som finns. Om det också funnes en databastabell över sektioner (h2-rubriker, ==) som finns i varje sida, så skulle den kollen också gå snabbt. När en ny version av en sida sparas (vilket inte är jätteofta) behöver den tabellen förstås uppdateras. --LA2 (diskussion) 24 mars 2022 kl. 14.20 (CET)
- Flikar bara in att nu finns det ett spanskt uppslag för bar#Spanska, men när exemplet ovan framfördes så var detta ej fallet. Svenji (diskussion) 24 mars 2022 kl. 14.35 (CET)
- Att det går snabbt att kolla om sidan finns, beror ju på att det finns en databastabell över sidor som finns. Om det också funnes en databastabell över sektioner (h2-rubriker, ==) som finns i varje sida, så skulle den kollen också gå snabbt. När en ny version av en sida sparas (vilket inte är jätteofta) behöver den tabellen förstås uppdateras. --LA2 (diskussion) 24 mars 2022 kl. 14.20 (CET)
- Ur vårt (svwikts) perspektiv, är anledningen till att det går snabbt med grönlänkar, att länkarna på sidan redan är särskilt markerade: dom är röda. Så allt skriptet behöver göra är (i princip) att ändra röda länkar till gröna.
- Det skulle gå att lösa tillräckligt effektivt via ett externt verktyg med full tillgång till innehållet på vår wiki (t.ex. på Toolforge), men det är inget som jag kommer göra. Skalman (diskussion) 26 mars 2022 kl. 22.36 (CET)
Partikelverb för verb som inte tillhör första eller andra konjugationen
redigeraJag skapade i går göra upp och i dag se över.
Notera de fina partikelverbsböjningsmallarna till höger.
Tyvärr gör dessa mallar så att artiklarna hamnar i kategorin Kategori:Svenska/Andra konjugationens verb, vilket är olyckligt.
Detta beror antagligen på att grammatikmallen i båda fallen är {{sv-verb-er}}.
Men jag tycks inte ges någon möjlighet att välja {{sv-verb}} (finns inte) och {{sv-verb-ar}} är förstås inte på något sätt bättre (första konjugationen).
Tittar man på respektive grundverbs artikel så ser man att göra också använder {{sv-verb-er}} och också hamnar i kategorin Kategori:Svenska/Andra konjugationens verb, vilket även det är olyckligt. Tittar jag på se så finns den artikeln inte i någon olämplig kategori, men den använder mallen {{sv-verb-r}} som inte tycks ha stöd för partiklar över huvud taget.
Så vad skall en stackars artikelförfattare som jag göra för att allt skall bli rätt?
Notera att mallarnas dokumentation säger "Om något ord inte passar in i någon av dessa beskrivningar kan valfri mall användas.", och visst kan jag få grammatikrutan att se bra ut visuellt även med en semantiskt olämplig mall, men kategorin blir ju fel.
--Andreas Rejbrand (diskussion) 27 mars 2022 kl. 20.08 (CEST)
- Verbet "göra" hamnar också i Kategori:Svenska/Andra konjugationens verb. Jag har aldrig förstått hur detta med "starka" och "avljundsklassade" verb ska funka. Jag har ett eget system med 19 verbklasser. Jag ser ingen snabblösning utom att ta bort dessa kategorier. Taylor 49 (diskussion) 27 mars 2022 kl. 22.29 (CEST)
- Nu skapade jag rå för som också hamnar i kategorin Kategori:Svenska/Första konjugationens verb trots att rå är av tredje konjugationen. --Andreas Rejbrand (diskussion) 2 april 2022 kl. 18.30 (CEST)
- Den tidigare artikeln rå på hamnar i kategorin Kategori:Svenska/Andra konjugationens verb vilket är lika illa.
- Missförstå mig inte: Våra grammatikmallar är superbra och den automatiska konjugationskategoriseringen fungerar bra i många fall (dock inte för rå ser det ut som). Men det verkar som om utvecklaren glömt bort partikelverben helt och hållet. --Andreas Rejbrand (diskussion) 2 april 2022 kl. 18.33 (CEST)
- Många partikeluppslag som finns sedan tidigare är också felkategoriserade. T.ex. är komma ut kategoriserat som första konjugationen (*jag kommar, jag kommade, har jag kommat), vilket är uppenbart fel. --Andreas Rejbrand (diskussion) 2 april 2022 kl. 19.43 (CEST)
- @Andreas Rejbrand något IP gjorde redigeringen att lägga till kategorierna utifrån vilken mall som används [2]. Om det inte ger ett korrekt och tillförlitligt resultat, tänker jag att kategoriseringen inte ska ske. Det verkar rimligt att helt enkelt avlägsna koden som placerar sidorna i dessa kategorier. ~ Dodde (diskussion) 6 april 2022 kl. 20.11 (CEST)
- Ja, jag tycker också att vi tar bort dem tills vidare. --Andreas Rejbrand (diskussion) 12 april 2022 kl. 19.19 (CEST)
- ✔ Verkställt. Taylor 49 (diskussion) 13 april 2022 kl. 08.27 (CEST)
Chrome
redigeraHej! Jag vet inte om det är min gamla MacBook Air som håller på att ge upp, men sen igår kväll har jag problem med vissa funktioner på Wiktionary med Google Chrome. Bland annat går inte utfällbara grammatikmallar och översättningslistor att klicka på och därför heller inte att visas. Nu har jag gått över till Firefox. Svenji (diskussion) 5 maj 2022 kl. 13.26 (CEST)
Använda mallar från andra wiktionaries
redigeraVad är rätt sätt att använda mallar från ex. engelska wiktionary? Hade tänkt se över en del arabiska ord och mallar som denna https://en.wiktionary.org/wiki/Template:ar-IPA skulle vara väldigt trevliga att ha. Är rätt sätt att kopiera över den till svenska wiktionary eller finns det något bra sätt att använda den direkt som jag bara inte hittar? Dgse87 (diskussion) 7 maj 2022 kl. 13.03 (CEST)
- +1, även för andra språk (persiska, hebreiska, tigrinya, hindi, m.fl. Svenji (diskussion) 19 maj 2022 kl. 15.40 (CEST)
- Vi brukade inte göra så. Jag måste varna för omfattande beroendeväv som dessa mallar har. Du kan inte bara kopiera "ar-IPA" och då är det gjort. Den kommer att kräva andra mallar, som i sin tur kommer att bero av fler mallar och moduler. Det kommer att sluta med att 99% av mallar från en wiktionary finns här och duplicerar 99% av arbete av våra traditionella mallar, och ingen kan underhålla det hela. Många wiktionaryer har gjort så och slutat med en jättesvinstia. Taylor 49 (diskussion) 19 maj 2022 kl. 22.00 (CEST)
- Så vad är alternativen? Att inte använda mallar då vi är en mindre wiki? Att bygga egna mallar som är enklare att underhålla men som inte är lika fullt utvecklade?
- Att bara strunta i att använda mallar känns lite väl drastiskt?
- Men oavsett vilket så tolkar jag ditt svar som att det inte finns något sätt att använda mallar som "bor" på engelska wiktionary direkt utan det enda alternativet som finns är att återskapa så mycket som vi kan/vill/orkar underhålla här på svenska Wiktionry? Dgse87 (diskussion) 19 maj 2022 kl. 23.19 (CEST)
- > Så vad är alternativen?
- kopiera mallar efter diskussion och konsensus, medvetna om svårigheter, och bestämda hur långt vi ska gå med detta (tydligare: Ska vi i slutändan slänga alla förhandenvarande mallar, och köra till 100% på ett system kopierat från en wiktionary?)
- skapa egna (kanske enklare) mallar
- köra utan mallar i vissa fall där sådant är rimligt (till exempel exempelmenigar)
- > använda mallar som "bor" på engelska wiktionary direkt
- Direkt går det verkligen inte. Vi har mallen i två versioner
{{härledning}}{{härledning-}}-- lite olyckligt, ingen har hittills hunnit fixa den bättre. Taylor 49 (diskussion) 19 maj 2022 kl. 23.38 (CEST)- Ok! Låter rimligt även om det som "utomstående" känns lite olyckligt att inte alla mallar på alla wiktionaries ligger i samma "namespace". Såklart inget vi här kan göra nåt åt men ja...
- Då blir nästa fråga (ni får säga till om vi ska bryta ut det till en ny "trådstart")
- Hur/var skall diskussioner tas kring mallar. Antar att det är bra både att diskutera vilka vi behöver men också vilka som ska kopieras från andra wiktionaries.
- Startar man en diskussion här på teknikvinden eller finns det något annat ställe där mallar redan diskuteras? Dgse87 (diskussion) 20 maj 2022 kl. 09.05 (CEST)
- > Så vad är alternativen?
- Vi brukade inte göra så. Jag måste varna för omfattande beroendeväv som dessa mallar har. Du kan inte bara kopiera "ar-IPA" och då är det gjort. Den kommer att kräva andra mallar, som i sin tur kommer att bero av fler mallar och moduler. Det kommer att sluta med att 99% av mallar från en wiktionary finns här och duplicerar 99% av arbete av våra traditionella mallar, och ingen kan underhålla det hela. Många wiktionaryer har gjort så och slutat med en jättesvinstia. Taylor 49 (diskussion) 19 maj 2022 kl. 22.00 (CEST)
Här i teknikvinden är det bästa stället att diskutera mallal som ännu inte finns, eller spörsmål som rör flera mallar. Vi har redan haft det ett fåtal gånger, se Wiktionary:Teknikvinden/Arkiv02#En_stilla_undran och Wiktionary:Teknikvinden/Arkiv02#Mall_för_exempelmeningar. Du är ute efter bland annat automatisk transkription. Jag har faktiskt önskat detta länge till den här wikin och några andra wikier, men inte hunnit att göra något alls. Som sagt, kopiering från en wiktionary är vanlig, men medför allvarliga nackdelar. Så har en wiktionary flera gånger gjort om sitt system. Vid varje tillfälle gick en bot igenom alla sidor (flera 1'000'000) och anpassade alla mallanrop. Detta skedde så klart enbart inom en wiktionary, men INTE vid andra wiktionaryer dit delar av systemet hade kopierats. Resultatet vid dessa wikier är en blandning av flera generationer av systemet från en wiktionary bredvid varandra, en svinstia som funkar dåligt och ingen har koll på. Delvis tillkom det mallar från andra källor. Mallar, mallar, mallar, och moduler, moduler, moduler, massor med kod som mestadels saknar dokumentation, och duplicerar kod som redan finns mer än en gång annanstans.
"Template:ar-IPA" beror på en enda modul: "https://en.wiktionary.org/wiki/Module:ar-pronunciation", vilken i sin tur beror på 6 moduler "Module:links" "Module:languages" "Module:scripts" "Module:script utilities" "Module:parameters" "Module:IPA". Nästa nivå: "Module:languages" har 155 undersidor. Och slutet är ännu inte nått.
Det är inte så snabbt och smidigt att kopiera en mall från en wiktionary och ha den direkt.
Jag vill inte ha "Module:parameters" från en wiktionary, eftersom den är orimligt komplicerad och fungerar dåligt. Vi har {{#invoke:param}} som är enklare och sköter sig bättre.
Visst är en wiktionary störst och har saker som ingen annan har (automatisk transkription är en av dem), men den är inte alls perfekt eller bäst. Mycket görs där på ett onödigt komplicerat sätt ("Module:parameters" och översättningar är två exempel av många). Även syntaxen på uppslag är onödigt komplicerat.
Jag är i princip inte alls emot automatisk transkription baserad på kod från en wiktionary, men detta måste göras på ett vettigt, genomtänkt och efficient sätt, vilket inte är enkelt. Att snabbkopiera 2 eller 162 sidor är inte en bra början eller ett värdefullt bidrag till den här wikin, tyvärr. Taylor 49 (diskussion) 20 maj 2022 kl. 21.05 (CEST)
- Jag hör vad du säger och håller med dig :) Jobbar till vardags med att skriva kod så och svenska wiktionaries aktiva medlemmar verkar gå att räkna på två händer så håller verkligen med om att vi inte vill kopiera hundratals odokumenterade script med ogenomtänkt syntax "bara för att". Men bra då låter det som om jag får läsa på om hur mallar och moduler funkar och sen se om jag kan producera någonting vi kan diskutera. Dgse87 (diskussion) 21 maj 2022 kl. 21.14 (CEST)
Ska Mall:subst lägga till kategorin "Kod/Alla uppslag"
redigeraEnligt dokumentationen för https://sv.wiktionary.org/wiki/Mall:subst så ska mallen placera uppslaget i Kategori:Kod/Substantiv och Kategori:Kod/Alla uppslag. Men när jag använder
{{subst|ar}}
så verkar mallen bara lägga till Kategori:Arabiska/Substantiv men inte Kategori:Arabiska/Alla uppslag. Är dokumentationen fel eller är det en bug i mallen? –föregående osignerade kommentar är från Dgse87 (diskussion • bidrag)
- Den senare kategorin är en s.k. dold kategori. Du kan sätta på visningen av dolda kategorier under Inställningar > Utseende > Avancerade alternativ > Visa dolda kategorier. --Andreas Rejbrand (diskussion) 7 maj 2022 kl. 19.51 (CEST)
- Fantastiskt :) Tack Dgse87 (diskussion) 7 maj 2022 kl. 23.54 (CEST)
Det går trögt att lägga till översättningar
redigeraNär jag lägger till översättningar och klickar "förhandsgranska" så tar det ibland 3 sekunder innan något händer. Denna tröghet har jag upplevt de senaste dagarna, men inte tidigare. Har något förändrats som ger anledning till detta? Ny sorteringsalgoritm? --LA2 (diskussion) 13 maj 2022 kl. 13.41 (CEST)
[CLOSED: FIXED] Betydelser
redigeraVarför visas inte värdet av parametern betydelser= (siffran 1 resp. 2) i mallarna / böjningsrutorna på sidan характерний? LA2 (diskussion) 14 juni 2022 kl. 12.24 (CEST)
Interwikilänkning av ordspråk
redigeraProblem
redigeraTexten nedan är med flit större för att interpunktionen ska synas:
- Rom byggdes inte på en dag.
- https://en.wiktionary.org/wiki/Rom_byggdes_inte_på_en_dag
- When in Rome, do as the Romans do.
- https://en.wiktionary.org/wiki/when_in_Rome,_do_as_the_Romans_do
- https://eo.wiktionary.org/wiki/Pasero_kaptita_estas_pli_bona_ol_aglo_kaptota.
- https://ru.wiktionary.org/wiki/pasero_kaptita_estas_pli_bona,_ol_aglo_kaptota
- https://fr.wiktionary.org/wiki/pasero_kaptita,_estas_pli_bona_ol_aglo_kaptota
Här har vi den självklara regeln att proverb ska läggas in i befintligt skick. Vid en.wiktionary tar de bort interpunktionen vid slutet men (konsequent nog) INTE inre interpunktion, och de börjar inte en mening med versal, enligt en regel som skapades för ca 20 år sedan. Övriga viktionaryer tog över vanan från en.wiktionary utan att fundera vidare eller alls. Cognate kräver exakt överensstämmelse (med minimala eftergifter) för att bevilja länken. Det går att skapa omdirigeringar, men problemet är att de ofta blir raderare vid andra wikier (en.wiktionary bryr sig inte om andra, de är ju störst, och de har alltid rätt). Det går att använda explicita interwikilänkar, men detta leder till en ensidig fördelning av bördan (sv.wiktionary ska ha både omdirigeringar och interwikilänkar, en.wiktionary ingenting) och medför risken att dessa interwikilänkar tas bort av misstag.
Se även:
- meta:Wiktionary/Technical improvements och meta:Wiktionary future
- meta:Requests for comment/Cross-wiki management of Wiktionary headwords using a Wikidata-like approach
Förslag till lösning
redigera@Användare:Teodor605 @Användare:Svenji @Användare:Skalman @Användare:PineappleSnackz @Användare:Pametzma @Användare:Moberg @Användare:LA2 @Användare:Gabbe @Användare:Dodde @Användare:Andreasl01 @Användare:Andreas Rejbrand
Alla kräver Phabricator.
A
redigera- skapa ett magiskt ord
__FUZZY_INTERWIKI__som skulle användas på alla wikier för alla uppslag med ordspråk - förbättra Cognate
- ifall magiskt ord inte finns, gör som det har gjorts sedan år 2017
- ifall magiskt ord finns:
- försök hitta en överensstämmesle på traditionellt sätt, ifall ingen träff
- försök igen men ta bort all interpunktion och gör bokstaven i början till en gemen på båda sidorna, till exempel "Rom byggdes inte på en dag." -> "rom byggdes inte på en dag", ifall flera träffar då prioriteras fullvärdiga sidor framför omdirigeringar och större sidor framför kortare
- försök hitta en överensstämmesle på traditionellt sätt, ifall ingen träff
- detta skulle väl kräva en fördubbling av hashtabellen som Cognate använder sig av
B (bättre?)
redigeraÄndra på WikiData:s regler och den tekniska restriktionen som beror på dem. Behåll grundprincipen "NS 0 i wiktionary är utesluten från WikiData", men inför ett undantag. Skapa en Q-item "wiktionary lemma needing manual interwiki coordination", och alla Q-item som är "instance of" den får länkas till NS 0 i wiktionary. Ifall en wiktionarysida är länkad till WikiData då gäller WikiData, annars Cognate. En bot går regelbundet igenom alla Q-item i fråga och lägger till sidor som har namn identiska med de som redan finns (enligt Cognate:s sätt), vid flera träffar prioriteras fullvärdiga sidor framför omdirigeringar och större sidor framför kortare. d:Q31897455 d:Q1390514.
Taylor 49 (diskussion) 1 juli 2022 kl. 23.50 (CEST)
- Vad är det för en mystisk "regel som skapades för ca 20 år sedan"? Och som bara sv.wiktionary känner till? Den enklaste lösningen är väl att vi rättar in oss i ledet och följer praxis på en.wiktionary. --LA2 (diskussion) 2 juli 2022 kl. 23.35 (CEST)
- @Taylor 49: Ledsen för sent svar, men jag skulle föreslå att de flyttas till formen utan punkt på slutet, samt att vi tog bort den stora bokstaven i början. Förutom på "Rom byggdes inte på en dag", som av förklarliga skäl även fortsättningsvis bör inledas med stor bokstav . Jämför meningar som
- Gammal är äldst, sägs det.
- Hon svarade att gammal är äldst.
- Lägg märke till att ordföljden gammal är äldst kan inledas med stor bokstav och avslutas med punkt. Men den behöver inte göra det. Därför tycker jag det är fel att uppslagsordet ligger på Gammal är äldst. (med stor bokstav och punkt). Det vore bättre att ha dem på gammal är äldst (utan punkt). Inte för att andra gör så, utan för att det helt enkelt är mer korrekt. Du kan jämföra med imperativformen av verb. Följande är en korrekt mening:
- Sjung!
- Däremot har vi imperativformen av sjunga på sidan sjung, inte Sjung!. Bara för att man kan börja med stor bokstav och avsluta med skiljetecken betyder det inte att man måste göra det. Gabbe (diskussion) 17 augusti 2022 kl. 13.12 (CEST)
- Jag tycker att det skulle vara okej att gå över till gemen + utan punkt. Skalman (diskussion) 17 augusti 2022 kl. 15.49 (CEST)
- Det finns alltid gränsfall såsom "Gammal är äldst.". Men
- When i Rome do as the Romans do.
- When in a hole stop digging.
- är väl en meningar och inte
- when i Rome do as the Romans do
- when in a hole stop digging
- Taylor 49 (diskussion) 20 augusti 2022 kl. 09.54 (CEST)
- @Taylor 49. Jämför med:
- Sjung!
- Det är en mening, eftersom det används som en mening. Följande är också en mening (med sex ord):
- Verbformen sjung stavas med fem bokstäver.
- Samma sak menar jag gäller med
- When in a hole stop digging.
- Det är en mening, eftersom det används som om det vore en mening. Men ordföljden måste inte användas som om det vore en fullständig mening. Här är ett exempel från Google Books [3]:
- Indeed, adherence to the Law of Holes (when in a hole, stop digging) would be a welcome start.
- Hur kommer det sig att det omsluts av parenteser ser ut så där? Borde inte det börja med stor bokstav efter vänsterparentesen och sluta med punkt före högerparentesen? Svaret på de frågorna har att göra med hur många meningar det finns i raden ovanför. Då måste man skilja på det som kallas en grafisk mening och en anförd mening. Se Svenska Akademiens Grammatik för definition av vad dessa två koncept innebär. "Grafisk mening" finns t.ex. definierat på sidan 177 i volym 1. Ovanför finns det en grafisk mening, som börjar med ordet "indeed" och slutar med ordet "start". Det som står innanför parentesen är inte en grafisk mening. När man citerar andra, antingen om det är ordagranna citat från en specifik person, eller mer generella hänvisningar till vad som "sägs" i form av talesätt, då behöver man inte alltid börja med stor bokstav och avsluta med punkt. Därför menar jag att talesätt av typen
- when in a hole stop digging
- inte bör inledas med stor bokstav och avslutas med punkt här på Wiktionary. Det går att använda dem som en (grafisk) mening, men man behöver inte göra det. Gabbe (diskussion) 20 augusti 2022 kl. 10.20 (CEST)
- @Taylor 49. Jämför med:
- Taylor 49 (diskussion) 20 augusti 2022 kl. 09.54 (CEST)
Låt mig göra det ännu mer tydligt varför jag tänker som jag gör. När vi funderar på om ett visst uppslagsord ska börja med stor bokstav kan välja mellan ett par olika principer att följa:
- Princip 1 Om ordet kan börja med stor bokstav ska artikeln också göra det.
- Princip 2 Om ordet måste börja med stor bokstav ska artikeln också göra det.
Ta följande mening:
- Det här är en mening.
Eftersom "Det" börjar med stor bokstav skulle det enligt princip 1 innebära att artikeln som nu finns på det ska flyttas till Det. Jag antar att alla håller med mig om att följderna skulle bli bisarra ifall vi tillämpade princip 1. Vi kan jämföra med följande mening:
- Italiens huvudstad heter Rom.
Enligt princip 2 så skulle artikeln om staden vara på sidan Rom, inte rom. Låter högst förståndigt. Att det finns ett mellanrum i artikelns titel tycker jag inte förändrar saken. Alltså har vi liten bokstav i början av såväl köpa som köpa in och köpa grisen i säcken.
Så vad händer när vi börjar prata om ordspråk? Ta följande två exempelmeningar för att illustrera:
- Osvuret är bäst.
- Detta är en korrekt mening, men osvuret är bäst.
Enligt princip två så skulle alltså artikeln om ordspråket hamna på osvuret är bäst. Istället har vi tillämpat princip 1, fast bara för ordspråk. Det menar jag är inkonsekvent och fel. Bättre, i min mening, vore att tillämpa princip 2 även här. Ett motsvarande argument som gäller det för stor bokstav i början kan även appliceras på om vi ska avsluta med punkt. Ta följande mening:
- Osvuret är bäst, sägs det.
Där blir det kommatecken, inte punkt, efter "bäst". Motsvarigheten till princip 1 skulle ha punkt i slutet. Motsvarigheten till princip 2 skulle skippa punkten. Gabbe (diskussion) 22 augusti 2022 kl. 08.19 (CEST)
Mall för franskt uttal
redigeraPå engelska Wiktionary finns en mall jag tycker är himla fiffig: {{fr-IPA}}. Den tar ett givet ord och genererar automatiskt dess korrekta uttal i IPA. Även om det finns specialfall som behöver hanteras manuellt så är den förvånansvärt fullständig. Den bygger på en Lua-modul som, vad jag förstår, borde vara ganska enkel att importera direkt till svenska Wiktionary. Om någon känner sig manad att göra det vore jag mycket tacksam! Gabbe (diskussion) 16 juli 2022 kl. 19.44 (CEST)
- Såg först nu att det fanns en liknande diskussion ovanför om den arabiska mallen av det slaget. Jag antar att motsvarande invändningar (tyvärr) är applicerbara även i det här fallet? Gabbe (diskussion) 16 juli 2022 kl. 19.48 (CEST)
- Sådana mallar finns oxxå för esperanto, finska och ytterliagre språk. Det finns dessutom fiffiga mallar för transkription av diverse icke-latinska alfabet. Detta är visst på min att-göra listan, men väl inte enkelt. Taylor 49 (diskussion) 17 juli 2022 kl. 17.18 (CEST)
- Har fått det igång med Modul:eo-IPA. Kanske imorgon finska och i övermorgon franska. Taylor 49 (diskussion) 17 juli 2022 kl. 19.14 (CEST)
- @User:Gabbe: Finskan var betydligt svårare men även den verkar funka nu: Modul:fi-IPA. Taylor 49 (diskussion) 20 juli 2022 kl. 00.32 (CEST)
- Grymt, tack (på förhand)! Gabbe (diskussion) 20 juli 2022 kl. 08.08 (CEST)
- Åh vad bra, Taylor! Om du känner att du har koll på det, vill du spana in {{es-IPA}} också? Svenji (diskussion) 20 juli 2022 kl. 08.21 (CEST)
- Dock är väl kanske nyttan allra störst hos språk med icke-latinska skrifter, kanske persiska, arabiska och hebreiska? Jiddisch är jag osäker på om det funkar för, då de har ett fonetiskt skrivsätt, med undantag från orden med semitisk rot - som följer hebreiskan. Det är alltså inte meningen att lägga allt detta jobb på ditt bord, Taylor. Jag tänker bara öppet. Ska kolla in modulerna ikväll om jag får tid. Svenji (diskussion) 20 juli 2022 kl. 08.26 (CEST)
- Går det att lägga till så att mallen även skriver ut "uttal:"? Nu ser det lite otydligt ut, om vi inte planerar att ändra om uttal till en #:{{uttal|}} Svenji (diskussion) 20 juli 2022 kl. 22.48 (CEST)
- Åh vad bra, Taylor! Om du känner att du har koll på det, vill du spana in {{es-IPA}} också?
- Det går säkert ... men sättet hur jag nyligen utökade den urgamla mallen
{{ipa}}kan upfattas som lite provisorisk. Jag skulle helst ha en helt ny mall+modul som tar över från den oturliga mallen{{uttal}}som inte tillåter att lägga till flera uttal, inte stöttar anmärkningar, och ibland (ca 230 sidor) kombineras med "ipa". Taylor 49 (diskussion) 20 juli 2022 kl. 23.11 (CEST)
- Det går säkert ... men sättet hur jag nyligen utökade den urgamla mallen
- @User:Gabbe @User:Svenji: Jag har tittat på franskan lite grann. Svårigheter finns gott om, modulen verkar befinna sig just nu i en övergångsfas, bara 589 testfall går åt helvete för närvarande, och modulen är koppad till en privat sandlåda. Ytterligare utmaningar gemensamma för alla språk på enwikt:
- dokumentationen för modulen är ofta obefintlig (dock vanligtvis bättre för mallen)
- modulen bygger oftast hela sektionen (enligt enwikt:s stilguide)
- ibland genereras det flera alternativa uttal (gäller för fr, men detta borde göras även för eo, och det finns säkert ytterligare)
- ibland genereras det []-uttal och //-uttal (gäller för bland annat fi)
- ibland behöver modulen "hjälp" AKA "respelling" (gäller för fi och fr)
- ibland behöver modulen ordklassen ("pos" på engelska) (gäller för fr)
- manuellt inmatade uttal måste sammanföras med dessa som genereras automatiskt på ett lämpligt sätt
- det finns bara 152 moduler (ingen av de för engelska), men tyvärr ingen helhetslösning, varje modul har sitt eget sätt att ta itu med de gemensamma arbetena
- Vad ska jag fokussera på nu? fr, es, eller en helhetslösning för svwikt, dvs en ersättning för
{{ipa}}och{{uttal}}som moduler för enskilda språk skulle kunna kopplas till? Det optimala vore en crosswiki-helhetslösning, men enwikt har haft sin lilla stora privata svinstia under 20 år, och det kommer väl att vara svårt dvs omöjligt att få fram en konsensus att göra om detta. Taylor 49 (diskussion) 23 juli 2022 kl. 15.03 (CEST)
- @User:Gabbe @User:Svenji: Jag har tittat på franskan lite grann. Svårigheter finns gott om, modulen verkar befinna sig just nu i en övergångsfas, bara 589 testfall går åt helvete för närvarande, och modulen är koppad till en privat sandlåda. Ytterligare utmaningar gemensamma för alla språk på enwikt:
- @User:Taylor 49: När jag ställde min fråga längst upp så hade jag ögnat igenom modulen på enwikt lite som hastigast. Jag trodde att det handlade om att skarva den en smula för att få den att funka på svenska wiktionary. Fila lite på hörnen, liksom. Om det är så att det skulle krävas nån slags "Extreme Home Makeover", så känn inte att du behöver göra det för min skull. Så svårt är det inte att klipp-och-klistra IPA:n från enwikt. Oavsett så dubbelkollar jag alltid uttalet i en icke-Wiktionary-källa som jag litar på innan jag inför det här. Av de alternativ du räknade upp är det helhetslösningen för svwikt jag skulle rösta för. Gabbe (diskussion) 23 juli 2022 kl. 15.50 (CEST)
Jag har hittat ett fel i mallen {{fr-verb-dire}} som jag är lite osäker på hur jag ska rätta till. Det gäller andra person plural (vous). För indikativ presens ska det bli dites, precis som det ser ut just nu. Men detta gäller bara för dire. För alla andra verb med "samma" böjningsmall (som contredire, interdire, prédire) ska den formen istället sluta på "disez". Ta till exempel interdire. Just nu blir det "interdites" där, vilket är fel. Det ska bli "interdisez".
Samma sak gäller för andra person plural av presens imperativ. Just nu står det "ditez", vilket är helt felt. Det ska egentligen bli dites (respektive interdisez). Gabbe (diskussion) 22 juli 2022 kl. 08.10 (CEST)
SAOB2IPA
redigeraEn annan tanke, när jag har dig på tråden, är något slags script som korrekt omvandlar uttalet på SAOB till IPA. SAOB använder ett helt eget system. Ta till exempel skjorta. De säger att det uttalas ʃω3rta2 och ʃωr3ta2. Om jag fattat det rätt motsvarar det /ˈɧu:rta/ respektive /ˈɧʊrta/. Särskilt förvirrande är det bland annat att ifall bokstaven "a" har en eller två "våningar" innebär på SAOB precis motsatsen mot vad det betyder i IPA (eller?). Detta anger de dessutom via om bokstaven står innanför <span class="StorKursiv"> eller inte. En korrekt IPA-ifiering av uttalet för svenska ord känner jag inte till någon ordbok som har, varken online eller offline. Det skulle kunna vara något som sätter svenska Wiktionary på kartan, så att säga.
Som sagt, bara en tanke. Gabbe (diskussion) 23 juli 2022 kl. 15.50 (CEST)
- @User:Gabbe: Det går säkert, och betyder jobb, och kanske mer. Men ska det vara en modul, en javascript eller en bot? Det skulle gå att göra en bot som går igenom hela SAOB, läser ut uttalet, konverterar, och lägger till i vår wiktionary. Men är det lagligt att göra så? Känner sig någon manad att skriva till Svenska Akademien och begära tillstånd för sådant tillslag? Min bot är ingen pirat. ;-) Jag håller med att uttal för alla svenska ord medelst IPA är mycket önskvärt. Jag har flyttat Gabbes text till ett nytt avsnitt. Taylor 49 (diskussion) 23 juli 2022 kl. 16.11 (CEST)
- @User:Taylor 49: Den rättsliga biten är jag inte så oroad för. Jag har slängt iväg ett mejl till dem för undanröjandet av tvivel. Gabbe (diskussion) 23 juli 2022 kl. 17.00 (CEST)
Såndlåda för mallar med tillhörande moduler
redigeraOm jag vill skapa en mall med moduler "på prov", så att säga, finns det något sätt att göra det på som är bättre? Vore det till exempel okej att jag skapade {{Gabbes-test}} tillsammans med Modul:modultesttesttest här, eller... ? Gabbe (diskussion) 24 juli 2022 kl. 10.22 (CEST)
- Gör gärna det. Det finns redan Modul:TEST och Mall:TESTTEST. Obs: återskapa inte "Modul:test" (pga javascript). Säg till när jag ska radera skräp som din testverksamhet har efterlämnat. Taylor 49 (diskussion) 24 juli 2022 kl. 21.34 (CEST)
- @Användare:Taylor 49: Jag testade lite med Mall:TESTTEST, Modul:TEST och Modul:TESTTESTTEST, men jag är klar nu. Det går bra att radera samtliga. Gabbe (diskussion) 26 juli 2022 kl. 16.33 (CEST)
Hur få moduler att returnera flera rader?
redigeraJag har gjort en ny mall som så småningom är tänkt att hantera konjugeringen av franska verb, såväl regelbundna som oregelbundna. Efter att ha fått det och funka dugligt på min Lua IDE tänkte jag att det var dags för nästa steg, att testa på Wiktionary. Därför har jag skapat {{fr-verb-test}}, som anropar Modul:fr-verb-artikel, som i sin tur anropar Modul:fr-verb-konj. Den första av modulerna är en slags "kaross", enbart menad att presentera värdena i det tabellformat som vi vill ha. Den andra av de två modulerna är en slags "motor", där själva konjugeringen sker. Tanken är att det ska gå att anropa den med {{fr-verb-test|artikelnamn=donner}}, {{fr-verb-test|artikelnamn=aller}}, {{fr-verb-test|artikelnamn=être}}, osv. för att testa.
Just nu stöter jag på två problem som inte dyker upp i min Lua IDE. Det första är att den första modulen inte verkar vilja hantera nya rader ("\n") som jag hade hoppats. Se rad 220 och 221 av Modul:fr-verb-artikel. Hur fixar jag det? Gabbe (diskussion) 27 juli 2022 kl. 08.05 (CEST)
- Jag har kollat lite grann. Har du skapat modulen "fr-verb-konj" själv? Jag vet inte vad du gjorde i din Lua IDE, men jag misstänker att att du testade enbart "fr-verb-konj" utan "fr-verb-artikel". Det stora problemet med "fr-verb-artikel" är inte nya rader, utan iden att denna genererar mallkod ie #switch #invoke mm. Du kan inte göra så pga parsningsprioriteterna. En modul kan generera HTML + wikilänkar + kategoriinläggningar (bäst), wikimarkup, eller innehållet för enskilda parametrar som matas in i andra moduler eller mallar. En modul får inte generera bland annat "nowiki", "noinclude", hela parametrar såsom "|permanentlybanned=true", eller anrop av andra moduler eller mallar. Slutsats: "fr-verb-artikel" enligt nuvarande design kommer aldrig att funka, och måste därför göras om från grunden. Taylor 49 (diskussion) 27 juli 2022 kl. 11.50 (CEST)
- @Taylor 49: Ja, jag har skrivit modulen "fr-verb-konj" helt själv. Jag har visserligen utgått från boken jag nämnde i de inledande kommentarerna. Siffrorna inom hakparentes på några av funktionerna fungerar som en slags källhänvisning. Det kan vara bra ifall man skulle vilja utöka modulen med mer "exotiska" oregelbundenheter. Då kan man fråga sig "är det verkligen så att verb av den här typen böjs på det sättet? vad baserar du det på?". Då finns källhänvisningen där i modulen. Boken innehåller dock bara en beskrivning av hur verben böjs och vilka som böjs på det sättet. Själva koden till "fr-verb-konj" har jag skrivit helt själv.
- Angående "fr-verb-artikel" så är det vad jag befarade. Jag går tillbaka till ritbordet med den. Det jag testade i min Lua IDE var att köra både "fr-verb-konj" och "fr-verb-artikel". Den senare gav textkod som output via "print()". Jag vet att vi inte får åberopa "print()" här på Wiktionary. Det som printats ut från "fr-verb-artikel" i min Lua IDE tog jag sen och klipp-och-klistrade in i WT:Sandlådan och tryckte på "visa förhandsgranskning". Jag jämförde sen med de mallar som redan fanns på sidor som aller, donner, osv. Allt såg bra ut. Här är ett exempel.
- Om jag vill att "fr-verb-artikel" ska mynna ut i något som är så likt output från
{{fr-verb-er}}som möjligt, ska jag alltså återskapa HTML + wikilänkar osv som den mallen mynnar ut i? Det verkar rätt bökigt. Hur hanteras då{{g-cell}}och liknande? Hur brukar andra göra för att konstruera mallar med tabeller utifrån modul-output? Gabbe (diskussion) 27 juli 2022 kl. 12.22 (CEST)
- Om jag vill att "fr-verb-artikel" ska mynna ut i något som är så likt output från
- PS Jag har lite infallsvinklar, så jag testar på ett tag så får vi se om jag kan hyfsa till det. Gabbe (diskussion) 27 juli 2022 kl. 12.39 (CEST)
- > klipp-och-klistrade in i Sandlådan och tryckte på "visa förhandsgranskning"
- OK, bra ide men sviker senare av ovan förklarade skäl.
- > återskapa HTML + wikilänkar osv som den mallen mynnar ut
- Precis.
- > hanteras då {mall|g-cell} och liknande
- * anropa via "expandTemplate" (bökigt)
- * anropa den underliggande modulen (bättre)
- * återskapa funktionen
- Taylor 49 (diskussion) 27 juli 2022 kl. 12.51 (CEST)
- Grymt, då tror jag att jag vet vad jag ska ta itu med härnäst. Tack! Gabbe (diskussion) 27 juli 2022 kl. 13.11 (CEST)
Vilka Unicode-tecken substitueras av Wiki-programvaran
redigeraJag hade en diskussion med @Dodde om testcases för moduler, och kom på följande fråga som är av mer allmänt slag. Så jag pingar in @Taylor 49 också och ställer den här istället.
När jag håller på med forngrekiska tecken vill jag bland ha att göra med
- ΰ (U+03B0 "Greek Small Letter Upsilon with Dialytika and Tonos")
- ΰ (U+1FE3 "Greek Small Letter Upsilon with Dialytika and Oxia")
Då kommer vän av ordning och säger till mig att det där är inte två olika tecken, utan samma tecken. Vanligen så ser tecknen identiska ut, oavsett om de lagras som U+03B0 eller U+1FE3. Här på Wiktionary verkar det som om mjukvaran automatiskt förvandlar dem bägge till U+03B0 utan att jag bett om det. Om det stämmer, finns det i så fall beskrivet någonstans i detalj vilka sådana slags Unicode-substitutioner som jag kan räkna med att programvaran gör? Gabbe (diskussion) 19 augusti 2022 kl. 14.17 (CEST)
- Det finns lite att läsa på enwikt och mediawiki.org, om det är till någon hjälp. Vill man kringgå normaliseringen verkar vanliga HTML-koder fungera (ΰ för ΰ). Andreasl01 (diskussion) 19 augusti 2022 kl. 15.32 (CEST)
- Grymt, tack! Det var precis svaret jag letade efter. Gabbe (diskussion) 19 augusti 2022 kl. 15.48 (CEST)
- Här finns mer [4], [5], [6], [7], [8]. Tydligen använder MediaWiki ett paket som heter utfnormal, som finns att granska på Github och kanske informationen du söker finns gömd i "UtfNormalData.inc" i den sista länken. ~ Dodde (diskussion) 19 augusti 2022 kl. 16.03 (CEST)
Avledning med accenter
redigeraSkulle {{avledning}} kunna använda mallen {{länk}}, så att man kan ange ryska ord med accenter? Jag vill alltså kunna skriva {{avledning|ru|избра́ть|ordform=pretpartpass}} -- LA2 (diskussion) 5 september 2022 kl. 17.52 (CEST)
- Jag ser inget hinder för det. Ska kika på det i natt. ~ Dodde (diskussion) 5 september 2022 kl. 18.09 (CEST)
- Det går säkert.
third_part = mw.ustring.format("[[%s#%s|%s]]", original_word, language, original_word)
- Jag ska titta på det vid tillfälle (ifall inte någon annan hinner innan).
link_target = import_lang.getEntryName(lang_code, base_text) -- remove diacrit
- BTW,
{{böjning}}har redan den här funktionaliteten (via "getEntryName"). Taylor 49 (diskussion) 5 september 2022 kl. 18.10 (CEST)
- BTW,
{{avledning}}ska nu funka enligt ditt förslag, @LA2. Ja, även Modul:link som{{länk}}anropar, använder lang.getEntryName. Bättre att anropa lang.getEntryName direkt från Modul:avledning än via Modul:link, som du föreslår, @Taylor 49, eftersom Modul:link tillåter en för varierad mängd indata än vad som är lämpligt för{{avledning}}. ~ Dodde (diskussion) 6 september 2022 kl. 01.14 (CEST)
Tack! {{avledning}} fungerar nu utmärkt med accenter, se избранный. Men {{böjning}} fungerar inte med accenter. Se избрал. --LA2 (diskussion) 6 september 2022 kl. 10.29 (CEST)
- @Användare:LA2 Jo:
#{{böjning|ru|verb|text=избра́ть}}Taylor 49 (diskussion) 6 september 2022 kl. 20.34 (CEST)
- Känns inte som att syntaxen fungerar som önskvärt. LA2:s exempel borde ju fungera. Visst borde väl 3= sköta detta automatiskt och text= bara användas om en "override" av 3= är nödvändig? ~ Dodde (diskussion) 6 september 2022 kl. 21.02 (CEST)
- Tidigare krävdes både "3=" och "text=". Finns det en möjlig situation där en override kan vara meningsfull? Ifall inte då kan "text=" helt avvecklas. Taylor 49 (diskussion) 6 september 2022 kl. 21.15 (CEST)
- Om vi får 3= att fungera med accenter, så är detta också vad gröna länken borde lägga till. Notera att избрал är skapad genom grön länk (från избрать) och sedan har jag redingerat in accenten i efterhand. --LA2 (diskussion) 6 september 2022 kl. 21.25 (CEST)
- Vad gröna länkar gör ansvarar enbart Skalman för. Det är enkelt att få 3= att fungera med accenter. Ska "text=" då avvecklas helt? Jag vill inte ha någon parameter utan ett vettigt användningsexempel. Taylor 49 (diskussion) 6 september 2022 kl. 21.35 (CEST)
- Vi kan sikta på att avveckla text=. Om hinder dyker upp på vägen får vi kolla på det då. Enda användningsområdet för text= som jag kan tänka mig jut nu är om Modul:lang/data saknar lämplig entryname-data för det specifika språket. I så fall kanske det är mer lämpligt att ändra i Modul:lang/data än att använda text=-parametern i böjningsmallen. ~ Dodde (diskussion) 7 september 2022 kl. 01.46 (CEST)
- Ja, vi får se till att de gröna länkarna fortsätter att fungera. ~ Dodde (diskussion) 7 september 2022 kl. 01.47 (CEST)
{{nollpos}} tas bort
redigera
Ändring genomförd: Motsvarande {{nollpos}} (CSS-kod: clear:both) sker automatiskt för alla ordklassrubriker och alla översättningsrubriker.
{{nollpos}}blir onödig och kommer tas bort- Parametern halv= till
{{ö-topp}}blir onödig och kommer tas bort
Bakgrund. Vi har använt {{nollpos}} ovanför översättningsrubriker, för att rubriken och översättningarna ska hamna nära varandra - det är snyggare. När detta infördes 2007, var det inte ett alternativ att lägga till automatisk nollpositionering på alla rubriker, eftersom vi använde många fler rubriker då, exempelvis ====Synonymer====. Under ett antal år fanns också en Javascriptlösning, men den var aningen buggig och gjorde att rubriker hoppade till rätt position, vilket är ganska fult.
Jag kommer uppdatera det här meddelandet med info om vad som händer utanför huvudnamnrymden när jag bättre förstår vilka behov vi har. Skalman (diskussion) 28 september 2022 kl. 22.10 (CEST)
- Statusuppdatering:
{{nollpos}}har döpts om till{{clear}}och kan inte längre användas på uppslag. Namnbytet syftar till att använda samma namn som Wikipedia. Det verkar som om den behövs på vissa dokumentationssidor, så därför tas mallen inte bort helt.- Parametern halv= har tagits bort från både
{{ö-topp}}och{{topp}}.
- Skalman (diskussion) 30 september 2022 kl. 00.18 (CEST)
Citat med translitterering
redigeraHej! Är det möjligt att lägga till tr= som en valbar parameter för citat? Som nu är går det inte att lägga till translitterering om citatet använder mall. Svenji (diskussion) 22 oktober 2022 kl. 18.28 (CEST)
- Ja, det vore ju önskvärt! Rent tekniskt lätt att lägga till. Och vore ju även bra för vanliga exempelmeningar. Borde det isåfall rymmas inom citatmallen eller ska en ny mall skapas? Hur vill vi att slutresultatet ska bli? En extra rad? Isåfall, kan vi utgå från att första raden börjat med #: eller finns andra alternativ? ~ Dodde (diskussion) 22 oktober 2022 kl. 18.47 (CEST)
- Att mallen saknas språkparameter är ju ett problem, dock. Och känns inte så bra att lägga till parametern språk= när vi är mitt uppe i att överföra språk= till 1= i flera andra mallar. ~ Dodde (diskussion) 22 oktober 2022 kl. 18.51 (CEST)
- Språkkodsparameter kanske inte måste lösas här och nu. @Svenji, jag har lagt till tr=-parametern för manuell translitteration i
{{citat}}så länge. Kan du kolla att det funkar som du tänkt dig? ~ Dodde (diskussion) 22 oktober 2022 kl. 22.48 (CEST)- Wow, det gick snabbare än jag hoppats, om ändå jag misstänkte det inte var en stor teknisk manöver. Tack för det, Dodde! Jag tycker transkriptionsraden ser bra ut, och bra att den står direkt under originaltexten. Är osäker på paranteserna, men någon typ av markering, att detta enbart är en transkribering och inte hur språket skrivs på modersmålet, bör nog finnas. Jag skulle gärna se att vi någonstans (kanske under Uttal:Ryska, Uttal:Jiddisch, Uttal:Arabiska m.m.) även har ett stycke där vi förklarar vilken transkriberingsmetod som vi används på uppslagen. Men det hör till en annan diskussion. Svenji (diskussion) 24 oktober 2022 kl. 21.59 (CEST)
- Jag har också ett annat problem när jag skrivit citat med skrivsystem som går från höger, att fetmarkeringen hamnar helt off, hur jag än vrider och vänder. Några gånger har jag dock oförklarligt lyckats få det tillrätta genom att felplacera dem. Vet inte om detta också går att lösa på ett enklare sätt. se t.ex. på נוסח. Svenji (diskussion) 24 oktober 2022 kl. 22.06 (CEST)
- Språkkodsparameter kanske inte måste lösas här och nu. @Svenji, jag har lagt till tr=-parametern för manuell translitteration i
- Att mallen saknas språkparameter är ju ett problem, dock. Och känns inte så bra att lägga till parametern språk= när vi är mitt uppe i att överföra språk= till 1= i flera andra mallar. ~ Dodde (diskussion) 22 oktober 2022 kl. 18.51 (CEST)
- @Svenji Detta är definitivt fråga om en eller flera buggar. Jag börjar med att ta bort dina apostrofer. Första konstigheten är att när den exempelmeningen i wikitexten inkluderar en radbrytning så blir orden omkastade så att texten ser ut så här:
digitalishn '''nusekh'''.|publ=The Yiddish Daily Forward|.פֿון הײַנט אָן און ווײַטער וועלן מיר זיך אין גאַנצן אָפּגעבן מיט אונדזער דיגיטאַלישן נוסח|Från och med idag kommer vi att helt ägna oss åt vår
- ...men när jag flyttar ner den hebreiska texten på en egen rad så faller orden på plats:
digitalishn '''nusekh'''.|publ=The Yiddish Daily Forward |.פֿון הײַנט אָן און ווײַטער וועלן מיר זיך אין גאַנצן אָפּגעבן מיט אונדזער דיגיטאַלישן נוסח|Från och med idag kommer vi
- Om jag redigerar i det första läget så blir resultatet helt knasigt. Så jag utgår ifrån det nedre exemplet ovan.
- Om jag nu placerar ut ''' till vänster och till vänster om "נוסח", så tolkas den vänstra ''' som en separat "left-to-right"-textsträng, medan den högra hamnar som en del av den hebreiska meningens "right-to-left"-textsträng.
- Fast det ser rätt ut i wikitexten, så renderas det hela helt fel.
- Ett sätt att göra så att det renderas rätt är att flytta den vänstra ''' längst ut till höger:
|.פֿון הײַנט אָן און ווײַטער וועלן מיר זיך אין גאַנצן אָפּגעבן מיט אונדזער דיגיטאַלישן '''נוסח'''|Från och med idag kommer vi att helt
- Exakt detta blir också resultatet när man markerar ordet man vill fetmarkera och klickar på wikitexteditorns "F"-knapp.
- Av någon outgrundlig anledning så flyttar den alltså bort den vänstra ''' och placerar den sist. Av någon ännu outgrundligare anledning gör den inte detsamma med punten, utan den hanteras och blir istället en del av "right-to-left"-textsträngen.
- Den resulterande HTML-koden som genereras av detta, och som alltså renderas på ett sätt så att det ser korrekt ut, blir den här i min Chrome-webbläsare:
<i> .פֿון הײַנט אָן און ווײַטער וועלן מיר זיך אין גאַנצן אָפּגעבן מיט אונדזער דיגיטאַלישן <b>נוסח</b> </i>
- Så här ser det ut: https://sv.wiktionary.org/w/index.php?title=%D7%A0%D7%95%D7%A1%D7%97&oldid=3819164.
- Whaat. Jag kanske missar något uppenbart här, men jag ser inte hur detta kan leda fram till ett korrekt utseende, men så är jag heller ingen expert på det här med scripts olika läsriktningar eller hur det är implementerat i webbläsaren. FireFox håller med Chrome om att detta funkar. Det renderas korrekt i båda webbläsarna. Om jag däremot klistrar in HTML-koden direkt i webbläsaren, så flyttas punkten till andra sidan exempelmeningen. MediaWiki håller definitivt på och trollar med renderingen på något sätt, och flyttar punkten så att det ska se rätt ut, men jag kan inte riktigt följa hur det går till. Tyvärr så har man missat att se vad som händer med punkten när det sker en radbrytning mitt i exempelmeningen (testa att kolla på נוסח på mobilen). Punkten blir kvar på första raden, trots att meningen fortsätter på nästa. :/
- Eftersom fetmarkeringen visas rätt av e.m.m. fel anledning skulle jag råda till att inte fetmarkera ordet om det är det första eller sista i ett citat eller en exempelmening där språket som används läses från höger till vänster. Om den här buggen åtgärdas nån gång skull det kunna resultera i att alla sidor som en gång såg rätt ut, helt plötsligt inte gör det längre.
- Om fetmarkeringen är mitt i en mening funkar det, för då uppstår inte det här problemet.
- Problemet med punkten på fel rad vid radbrytning kanske är något som man skulle kunna åtgärda lokalt med Javascript. @Skalman, eller? ~ Dodde (diskussion) 25 oktober 2022 kl. 06.15 (CEST)
- Hellre än lösning på mall&modul-nivå än ytterligare obskyr JS. Men jag är ingen expert på RTL. Buggen kan reproduceras på en vanlig dator ifall en gör ramen smal. Taylor 49 (diskussion) 25 oktober 2022 kl. 21.31 (CEST)

- Wikivärlden behöver akut en förenkling och stabilisering, inte påhitt som krånglar till allt ytterligare. Taylor 49 (diskussion) 25 oktober 2022 kl. 22.19 (CEST)
- Ja, tydligen hade jag inte förstått hur allt detta funkade. Det jag trodde var buggar är, antar jag, "by design". Vem hade, som relativt novis på området, kunnat gissa att "right-to-left" och "left-to-right" inte hanteras tecken för tecken, utan i större enheter av right-to-left-text respektive left-to-right-text. Jag kan fortfarande inte förmå mig att tycka att redigering av right-to-left-text faller sig naturligt i en editor inställd för left-to-right-redigerande.
- Jag skapade nu en
{{rtl}}-mall som i sig inte gör redigeringen av dessa exempelmeningar att kännas mer naturlig, men, den verkar råda bot på "punkt-buggen" ovan och den förklarar iallafall ett sätt som man kan fetstila ett ord på, även i början eller slutet av en exempelmening med höger-till-vänster-text. I redigeringsläget ser det ibland knäppt ut, men det finns en förklaring till varför det ser ut så. Dock förstår jag knappt förklaringen som jag försökte skapa på{{rtl}}själv, så om nån vill försöka sig på att förbättra den, så kör på! ~ Dodde (diskussion) 26 oktober 2022 kl. 06.08 (CEST)- Tack och åter tack, Dodde! Ska teste rtl-mallen i några citat nu. / Svenji (diskussion) 10 november 2022 kl. 23.51 (CET)
- Wikivärlden behöver akut en förenkling och stabilisering, inte påhitt som krånglar till allt ytterligare. Taylor 49 (diskussion) 25 oktober 2022 kl. 22.19 (CEST)
Sortera vid redigering
redigeraNär jag sitter där och fyller i {{besläktade ord|...}} så ville jag gärna få listan sorterad innan jag sparar sidan. Finns det något smidigt sätt, kanske en finess eller modul för det? -- LA2 (diskussion) 8 november 2022 kl. 22.18 (CET)
- @LA2 En modul kan ändra indata till utdata, så en modul skulle teoretiskt kunna ta en osorterad lista från wikitexten (om den ges som argument i en mall, t.ex.
{{besläktade ord}}och _visa den_ som om den vore sorterad, men inte ändra den faktiska ordningen i wikitexten. Vill man ändra ändra den faktiskta ordningen i wikitexten så behövs JavaScript som bl.a. finesser baserar sin funktionalitet på. Vi har en finess som vi kallar för "Tidy" som vi håller på och jobbar på som gör den här typen av grejer. Bra förslag. Vi kan absolut ha med förslaget på önskelistan över funktionalitet. Jag la till det [9]. Jag tänker dock att sortering generellt inte är helt trivialt att få till om man vill stödja specialfall, vilket nog behövs om det ska vara en del av Tidy-finessen. - Tills dess kanske man kan överväga att använda ett externt verktyg som t.ex. https://dataverktyg.se/sortera. Man kan ju också skapa egna script som kan göra det man vill, vilket är enklare än Tidy, men kanske bara funkar till viss del. Jag gjorde ett litet proof-of-concept på Användare:Dodde/sort template list.js. Du kan testa att importera det genom att lägga till textraden "importScript("Användare:Dodde/sort template list.js");" på sidan "Användare:LA2/common.js". Om du vill experimentera och göra egna ändringar så kan du kopiera över scriptet till din en undersida till ditt användarnamn "importScript("Användare:LA2/sort template list.js"); och isåfall uppdatera länken i "Användare:LA2/common.js. Scriptet fungerar så att du markerar en mall med innehåll t.ex. "{{besläktade ord|[[galopp]], [[hej]], [[hopp]]}}" så att markeringen inkluderar exakt hela mallen men ingenting mer. När du släpper muspekaren (måste släppas inuti textarean) så sker sorteringen. ~ Dodde (diskussion) 10 november 2022 kl. 14.31 (CET)
- Engelska Wiktionary har mallar som sorterar, t.ex. der3 och der4. Se t.ex. en:bil#Swedish. Men det är fult att en osorterad lista ligger i källkoden. Man vill ha källkoden snygg och likadan som utskriften, så att det är lätt att se eventuella dubletter.
- Din javascript-kod verkar fungera, men användargränssnittet är alltför kryptiskt. Jag vill ha en sortera-knapp ovanför redigeringsfönstret, intill pusselbiten för infoga mall och pennan för syntaxmarkering. När den knappen trycks, ska sorteringen tillämpas på det område som då är markerat. --LA2 (diskussion) 10 november 2022 kl. 18.22 (CET)
- @LA2 Ja, jag håller med om att man vill ha källkoden i samma ordning som utskriften. Javascriptet var bara ett proof-of-concept. Det visar att det går att fixa något lite snabbt och enkelt, men det har sina skavanker. Det är inte särskilt användarvänligt, det sker inte automatiskt, inte intuitivt, hanterar bara listor som består av ord utan komplicerad länksyntax, sorterar fel på många språk, inklusive svenska (ä sorteras före å, versaler soteras åtskilt från gemener) - för att det är så bokstäverna ligger i Unicode, ingen grafisk knapp att klicka på, men, kanske är det ändå bättre än ingenting om man känner till bristerna. Vill man ha det korrekt, ordentligt, prestandamässigt acceptabelt, kanske automatiskt, stödja alla språk, stödja mer udda syntax osv. Då är detta en rätt stor grej att fixa. Gärna det, men jag vill inte lova om eller i så fall när det kan bli aktuellt för mig att fördjupa mig i det, åtminstone. Jag skulle först se att vi kan få in språkkoderna i dessa mallar och att det kan ske smidigt genom Tidy, men vi är inte riktigt där, ännu, heller. ~ Dodde (diskussion) 10 november 2022 kl. 19.09 (CET)
- Har redigeringssidan inget enkelt sätt för finesser att lägga till knappar? --LA2 (diskussion) 11 november 2022 kl. 00.06 (CET)
- Jag har ingen aning - jag känner inte till något, men har heller inte letat. Skalman (diskussion) 11 november 2022 kl. 11.07 (CET)
- @LA2 Allt är nog enkelt om man kan det. Men jag har inte gjort det och för mig skulle det vara långt ifrån värt besväret. Det verkar som väldigt mycket krångel att gå igenom för att lägga till en bekvämlighetsknapp för en enskild användare. Om du själv vill göra ett försök, så kanske du kan hitta information här mw:Manual:Custom edit buttons. Se då till att knappen bara läggs till för dig personligen, om det nu ens är möjligt. Det finns två wikitext-redigerare som man kan behöva gå igenom proceduren för: 2010 wikitext editor och 2017 wikitext editor, den senare om/när den tas i bruk.
- Om du tänkte att det här skulle vara en knapp att lägga till för samtliga användare, tänker jag att det är en väldigt dålig idé för en funktion som har så otroligt många brister som jag listade en del av tidigare, och att det dessutom vore svårt att kommunicera dessa till användare av funktionen. Det skulle kunna leda till en hel del röra med felaktiga sorteringar och redigeringar.
- Vill man lägga till det här för alla, så är det bäst att göra det ordentligt och då tror jag att Tidy är en bättre väg att gå, men som sagt, det är ändå ett projekt av betydande storlek som vi pratar om även då. ~ Dodde (diskussion) 11 november 2022 kl. 11.40 (CET)
- Jag har ingen aning - jag känner inte till något, men har heller inte letat. Skalman (diskussion) 11 november 2022 kl. 11.07 (CET)
- Har redigeringssidan inget enkelt sätt för finesser att lägga till knappar? --LA2 (diskussion) 11 november 2022 kl. 00.06 (CET)
- @LA2 Är Användare:Andreasl01/sort template list - toolbar.js ungefär vad du hade tänkt dig? Jag har även skapat Användare:Andreasl01/sort template list.js som placerar ut en liten, klickbar ikon vid osorterade mallistor, så att man lätt kan se om något är i oordning. Andreasl01 (diskussion) 12 november 2022 kl. 21.54 (CET)
- @LA2 Ja, jag håller med om att man vill ha källkoden i samma ordning som utskriften. Javascriptet var bara ett proof-of-concept. Det visar att det går att fixa något lite snabbt och enkelt, men det har sina skavanker. Det är inte särskilt användarvänligt, det sker inte automatiskt, inte intuitivt, hanterar bara listor som består av ord utan komplicerad länksyntax, sorterar fel på många språk, inklusive svenska (ä sorteras före å, versaler soteras åtskilt från gemener) - för att det är så bokstäverna ligger i Unicode, ingen grafisk knapp att klicka på, men, kanske är det ändå bättre än ingenting om man känner till bristerna. Vill man ha det korrekt, ordentligt, prestandamässigt acceptabelt, kanske automatiskt, stödja alla språk, stödja mer udda syntax osv. Då är detta en rätt stor grej att fixa. Gärna det, men jag vill inte lova om eller i så fall när det kan bli aktuellt för mig att fördjupa mig i det, åtminstone. Jag skulle först se att vi kan få in språkkoderna i dessa mallar och att det kan ske smidigt genom Tidy, men vi är inte riktigt där, ännu, heller. ~ Dodde (diskussion) 10 november 2022 kl. 19.09 (CET)
Bugg med olagliga titlar
redigera- Användare:Кунимаро Сэнгэ (tydligen LTA, global blockering överhängande)
Varning: Denna sida kan endast redigeras av administratörer och andra användare med rättigheten tboverride eftersom den matchar följande post i listan över otillåtna titlar:
(?!(User|Wikipedia|File)( talk)?:|Talk:)[\P{Latin}A-Z]*[^\P{Latin}A-Z].*\p{Cyrillic}.* # Cyrillic + Non-ASCII Latin
| number of octet:s : 27 |
| index 0 beg code $D0=#208 length 2 extra $9A codepoint U+$041A dec #1'050 К |
| index 2 beg code $D1=#209 length 2 extra $83 codepoint U+$0443 dec #1'091 у |
| index 4 beg code $D0=#208 length 2 extra $BD codepoint U+$043D dec #1'085 н |
| index 6 beg code $D0=#208 length 2 extra $B8 codepoint U+$0438 dec #1'080 и |
| index 8 beg code $D0=#208 length 2 extra $BC codepoint U+$043C dec #1'084 м |
| index 10 beg code $D0=#208 length 2 extra $B0 codepoint U+$0430 dec #1'072 а |
| index 12 beg code $D1=#209 length 2 extra $80 codepoint U+$0440 dec #1'088 р |
| index 14 beg code $D0=#208 length 2 extra $BE codepoint U+$043E dec #1'086 о |
| index 16 beg code $20=#32 length 1 SPACE |
| index 17 beg code $D0=#208 length 2 extra $A1 codepoint U+$0421 dec #1'057 С |
| index 19 beg code $D1=#209 length 2 extra $8D codepoint U+$044D dec #1'101 э |
| index 21 beg code $D0=#208 length 2 extra $BD codepoint U+$043D dec #1'085 н |
| index 23 beg code $D0=#208 length 2 extra $B3 codepoint U+$0433 dec #1'075 г |
| index 25 beg code $D1=#209 length 2 extra $8D codepoint U+$044D dec #1'101 э |
| number of UTF8 char:s : 14 |
Jag ser ingen "Non-ASCII Latin" i namnet. Jag klassar detta som en bugg. Det borde gå att redigera disksidor för användarnamn som gick att registrera. Taylor 49 (diskussion) 12 november 2022 kl. 21.11 (CET)
- Det är väl prefixet "Användare" plus kyrilliska bokstäver i namnet som ställer till det. Taylor 49 (diskussion) 12 november 2022 kl. 21.14 (CET)
Ö+
redigeraFinns det någon bot som går runt och uppdaterar {{ö}} till {{ö+}} när nya sidor har skapats på andra språk av Wiktionary? Har det någonsin funnits? Eller borde det finnas? -- LA2 (diskussion) 12 november 2022 kl. 21.58 (CET)
- Jo det fanns en sådan för ca 17'000'000 år sedan, och borde IMHO finnas. Taylor 49 (diskussion) 12 november 2022 kl. 22.03 (CET)
- Skalman har kört detta för drygt 8 år sen. Se Skalbots användarsida. Frågan är vad status är på koden. Kan den fortfarande köras? @Skalman? ~ Dodde (diskussion) 13 november 2022 kl. 01.28 (CET)
- Nej, man skulle nog behöva omarbeta projektet en del för att få det att fungera. Skalman (diskussion) 13 november 2022 kl. 15.24 (CET)
- @LA2, jag håller på att skriva ett nytt skript för att uppdatera ö/ö+. Jag räknar med att kunna köra det snart - definitivt den här sidan om årsskiftet. Skalman (diskussion) 19 december 2022 kl. 09.03 (CET)
- Fixat. Jag har nu kört igenom alla sidor (14000 uppdateringar). Skalman (diskussion) 22 december 2022 kl. 17.41 (CET)
- @LA2, jag håller på att skriva ett nytt skript för att uppdatera ö/ö+. Jag räknar med att kunna köra det snart - definitivt den här sidan om årsskiftet. Skalman (diskussion) 19 december 2022 kl. 09.03 (CET)
- Nej, man skulle nog behöva omarbeta projektet en del för att få det att fungera. Skalman (diskussion) 13 november 2022 kl. 15.24 (CET)
- Skalman har kört detta för drygt 8 år sen. Se Skalbots användarsida. Frågan är vad status är på koden. Kan den fortfarande köras? @Skalman? ~ Dodde (diskussion) 13 november 2022 kl. 01.28 (CET)
Grundformslänk i böjningsmall
redigeraHur kommer det sig att ett utralt substantiv av andra deklinationen (t.ex. fisk) i sin böjningsmall får en länk till grundformen, vilket inte andra utrala substantiv (t.ex. flicka, katt) eller neutrala substantiv (t.ex. lejon) får? Andreas Rejbrand (diskussion) 22 november 2022 kl. 19.25 (CET)
- @Andreas Rejbrand Bra iakttagelse! Böjningsmallars kod ser olika ut, visar det sig nu när jag granskar den. Mallar som använder följande kod (t.ex.
{{sv-subst-n-or}}på flicka) får ingen länk: Böjningar av ''{{länka|{{{grundform|{{PAGENAME}}}}}}} {{{betydelser|}}}''- Medan mallar som använder följande kod (t.ex.
{{sv-subst-n-ar}}på fisk) får det: Böjningar av ''{{länk|<språkkod>|{{{grundform|{{PAGENAME}}}}}}} {{{betydelser|}}}''- Användning av
{{länk}}genererar länkar på formen[[ord#Språknamn|ord]], medan användning av{{länka}}genererar en enkel länk på formen[[ord]]. När "ord" är samma sak som sidnamnet gör MediaWiki om den enkla länken till icke länkad fetstilad text, till skillnad från länken som innehåller en ankare. - Wiktionary:Stilguide/Grammatik/Skapa_en_mall anger för närvarande att
{{länka}}ska användas, och det görs på 27 grammatikmallar [10], medan{{länk}}används av hela 332 grammatikmallar [11]. {{länka}}är äldre än{{länk}}och i början när den generella mallstrukturen utformades så använde alla grammatikmallar{{länka}}på det här stället. Det är nog därför det står kvar så i Wiktionary:Stilguide/Grammatik/Skapa_en_mall. I praktiken gav det samma resultat som att inte använda någon{{länka}}-mall över huvud taget. Så vi tänkte nog inte så mycket mer på det. Vi ville bara att uppslagsordet skulle vara fetstilat. När sedan{{länk}}skapades så övergick många mallar till att använda den istället för{{länka}}, och det resulterade i att ordet i grammatikmallen helt plötsligt blev länkat. Sen har man inte funderat så mycket mer på det, heller.- Jag förelår att vi tar bort länkningen helt och hållet i alla mallar. ~ Dodde (diskussion) 23 november 2022 kl. 04.36 (CET)
Artiklar med "soft hyphen" i titeln
redigera@Dodde, @Taylor 49: Det verkar finnas en del artiklar som felaktigt skapats med "soft hyphen" (U+00AD) i titeln. Jämför dessa två:
Vad ska vi göra med dem? Gabbe (diskussion) 23 januari 2023 kl. 11.08 (CET)
- Pingar @Skalman också. ~ Dodde (diskussion) 24 januari 2023 kl. 10.03 (CET)
- ✔ Löst "wätzig" plus alla föreslagna för radering plus alla som jag har hittat just nu. Flytta ifall det går, och föreslå omdirigeringen för radering. Ifall det inte går att flytta, föreslår den dåliga sidan för radering. Tack för utredningsarbetet. Taylor 49 (diskussion) 24 januari 2023 kl. 11.20 (CET)
- OBS att "soft hyphen" (U+00AD) är ett tydligt tecken på kopiering från en annan webbplats. Att kopiera bara titeln ger "bara" strul med titeln, att kopiera ett drabbad ord ger strul med detta ord (röd länk mm), att kopiera definitioner är värre. Tack till alla som hjälper att skapa den här ordboken, men PLAGIERA INTE från andra ordböcker. Taylor 49 (diskussion) 24 januari 2023 kl. 11.27 (CET)
Smartare "vad länkar hit"
redigeraSidan https://sv.wiktionary.org/wiki/Special:Länkar_hit/mutsedel innehåller bland annat länken Appendix:Bring/760. Tillåtelse, vilket jag använder för att lägga in #:{{seäven-bring|Tillåtelse}} i artikeln mutsedel. Kunde inte den wiki-texten stå direkt i sidan Special:Länkar_hit, så att jag bara kunde klippa ut och klistra in den på rätt ställe? Hur svårt kan det vara att få en sådan förbättring tillagd? -- LA2 (diskussion) 11 februari 2023 kl. 19.04 (CET)
Rak eller krokig apostrof i titeln
redigera@Dodde, @Taylor 49, @Skalman: Det verkar som om vi tillåter både rak apostrof (' U+0027) och krokig apostrof (’ U+2019) i artikelrubriken. Se följande två (olika):
Jag antar att detta bara ska vara en sida egentligen? Vad ska hända med sådana dubbletter? Gabbe (diskussion) 13 februari 2023 kl. 15.23 (CET)
- @Gabbe, jag är osäker på när/var det har diskuterats, men jag har ett svagt minne av att principen är att rak apostrof ska användas i titeln, eftersom den är lättare att skriva. Motsvarande titel med krokig apostrof kan skapas som en omdirigering. Skalman (diskussion) 13 februari 2023 kl. 22.31 (CET)
- Glömde skriva att jag har fixat denna omdirigering i detta fall. Skalman (diskussion) 13 februari 2023 kl. 22.31 (CET)
- Håller med. Använd rak ASCII apo "U+0027", krokig apo kan vara omdirigering. Taylor 49 (diskussion) 14 februari 2023 kl. 05.48 (CET)
- Glömde skriva att jag har fixat denna omdirigering i detta fall. Skalman (diskussion) 13 februari 2023 kl. 22.31 (CET)
Förenklig
redigera@User:Gabbe @User:Svenji @User:Dodde @User:Skalman @User:Pametzma @User:Tommy Kronkvist @User:Andreasl01: Det finns ett förslag på meta som skulle drastiskt förenkla arbetet med wiktionary. Taylor 49 (diskussion) 15 februari 2023 kl. 19.03 (CET)
- Skrev ett inlägg i diskussionen. ~ Dodde (diskussion) 15 februari 2023 kl. 19.31 (CET)
- Först tänkte jag att den här funktionen inte borde vara alltför viktig. En minut senare insåg jag hur mkt det skulle underlätta. Skalman (diskussion) 15 februari 2023 kl. 19.52 (CET)
Ändra sorteringsordning
redigeraHej! Hur kan jag ändra sorteringsordningen på spanska? Ordet élite behöver hamna bland övriga e i denna listan: Kategori:Spanska/Härledningar från franska. Svenji (diskussion) 5 mars 2023 kl. 15.57 (CET)
{{#invoke:härledning}}skulle behöva få stöd för sorteringsreglerna som anges i{{#invoke:lang/data}}.- @Taylor 49 eller @Dodde, är det nåt som ni kan fixa? Skalman (diskussion) 9 maj 2023 kl. 21.34 (CEST)
- @Dodde @Skalman ✔ DONE!!! bara 34 tester måste åtgärdas. Taylor 49 (diskussion) 9 maj 2023 kl. 22.36 (CEST)
- @Taylor 49 fint! Jag kan korrigera testerna om några dagar. ~ Dodde (diskussion) 13 maj 2023 kl. 03.46 (CEST)
- @Taylor 49 Fixat nu, men några av de felande testerna är korrekta, så 9 felande tester återstår att åtgärda. Verkar som om de automatiska ryska translitteringarna har slutat fungera. ~ Dodde (diskussion) 17 maj 2023 kl. 23.59 (CEST)
- @Dodde De var trasiga redan innan. Taylor 49 (diskussion) 18 maj 2023 kl. 05.54 (CEST)
Text till Wiktionary
redigeraPå Toolforge finns ett verktyg Text-to-lexemes (en del av systemet Ordia, skapat av dansken F Nielsen) där man kan mata in en text och få ut en tabell med ord, där det framgår vilka ord som finns respektive inte finns som Wikidata lexemes för det angivna språket. Skulle det gå att skapa ett liknande för Wiktionary? Jag skulle t.ex. kunna skriva in "to be or not to be, that is the question" och ange att jag vill att detta kollas mot befintliga engelska ord i svenska Wiktionary. Om då "question" inte har något uppslag, så får jag en röd länk, så att jag kan skapa det uppslaget. Detta skulle antagligen mycket underlätta skapandet av saknade uppslag. Kanske finns det redan något sådant verktyg, som jag inte känner till? -- LA2 (diskussion) 20 maj 2023 kl. 21.50 (CEST)
- Jag känner inte till något sådant verktyg, och jag skulle också uppskatta det. Vad jag gör för närvarande (som kanske är av intresse för dig, @LA2) är att jag använder RegEx, till exempel via https://regexr.com/. På den övre raden fyller jag i
[åäö\w]+och på den nedre raden (under "replace") har jag[[$&]]. Det resulterar i att
to be or not to be, that is the question
- förvandlas till
[[to]] [[be]] [[or]] [[not]] [[to]] [[be]], [[that]] [[is]] [[the]] [[question]]
- som jag sen klipp-och-klistrar i WT:Sandlådan och kollar vilka länkar som är röda. Det funkar inte exakt som det du beskriver (bland annat eftersom det inte tar hänsyn till vilket språk ordet är på, bara huruvida det finns ett uppslag). I min erfarenhet funkar det ungefär lika bra ändå. Gabbe (diskussion) 21 maj 2023 kl. 07.18 (CEST)
- Det skulle kanske vara möjligt att använda API:t.
const lang = "Svenska"; const text = "to be or not to be, that is the question"; const words = text.split(/[^\p{L}\p{M}-]+/u) // L = "letter" och M = "mark" (diakritiskt tecken), använder detta över /[^åäöÅÄÖ\w]+/ för att stöda andra skriftsystem (t.ex. kyrilliskt) .sort().filter((e, i, a) => e && e != a[i-1]); // tar bort dubbletter och potentiella tomma element new mw.Api().get({ action: "query", prop: "categories", clcategories: `Kategori:${lang}/Alla_uppslag|Kategori:${lang}/Adjektivformer|Kategori:${lang}/Adverbformer|Kategori:${lang}/Substantivformer|Kategori:${lang}/Verbformer`, titles: words }).then(response => { const missing = []; $.each(response.query.pages, (i, page) => { if (!page.categories) missing.push(page.title); }); console.log("[[" + missing.join("]], [[") + "]]"); });
- Koden ovan skriver ut de ord som saknar uppslag med det valda språket till konsolen, i det här fallet:
"[[question]], [[that]]". Om du ändrar språk till "Engelska" (stor begynnelsebokstav) skrivs"[[]]"ut, eftersom alla ord redan finns. - Det största problemet med den här metoden är att den troligen inte fungerar på längre texter då det förmodligen finns en gräns för hur många sidor som kan inkluderas i
titlesmen om behovet finns så skulle detta nog kunna lösas genom att dela upp förfrågan i flera mindre förfrågningar. Andreasl01 (diskussion) 21 maj 2023 kl. 10.17 (CEST)
- Jag tror ändå att ett verktyg (program på Toolforge) med inmatningsruta är vad som behövs. Sedan kan man inte API-kolla varje ord i varje inmatning, utan man behöver ha en databas (kanske baserad på senaste XML-dumpen) där man kan se vilka uppslag som finns. För de som inte fanns i XML-dumpen, kan man göra API-anrop, så att man inte rapporterar som saknade de uppslag som har skapats nyligen. --LA2 (diskussion) 21 maj 2023 kl. 16.04 (CEST)
- API:t är enligt https://www.mediawiki.org/wiki/API:Query#query:titles begränsat till 50 sidor per anrop så, ja, någonting annat skulle nog behövas för längre texter. På den här sidan (Teknikvinden) finns just nu 18 032 ord, varav 3 831 unika. Det skulle alltså bli 77 anrop vilket inte är rimligt. Man kan få behörighet att kolla 500 sidor per anrop, då skulle man bara behöva göra 8 stycken, men din idé att först kolla en databas och sen API:t låter ändå mycket bättre. Andreasl01 (diskussion) 21 maj 2023 kl. 17.17 (CEST)
- Jag tror ändå att ett verktyg (program på Toolforge) med inmatningsruta är vad som behövs. Sedan kan man inte API-kolla varje ord i varje inmatning, utan man behöver ha en databas (kanske baserad på senaste XML-dumpen) där man kan se vilka uppslag som finns. För de som inte fanns i XML-dumpen, kan man göra API-anrop, så att man inte rapporterar som saknade de uppslag som har skapats nyligen. --LA2 (diskussion) 21 maj 2023 kl. 16.04 (CEST)
Inloggning nekad
redigeraSvenji här, jag kan inte logga in på Wiktionary längre, möts av meddelandet:
- [d1b258bc-8104-4d27-b1c7-aeb4893a8ec5] 2023-05-31 16:53:49: Allvarligt fel av typen "Exception"". Däremot fungerar Wikipedia att logga in på som vanligt. Någon som vet vad som har hänt, eller ännu viktigare - hur kan jag åtgärda det? /Svenji 46.25.7.48 31 maj 2023 kl. 18.58 (CEST)
- Nu kunde jag logga in igen. Svenji (diskussion) 4 juni 2023 kl. 20.51 (CEST)
”Samma betydelse”
redigeraJag har noterat att en del artiklar, som t.ex. arkad, har med en etymologimall med texten ”samma betydelse” som betydelse:
- Belagt i svenska språket sedan 1771, franska arcade (”samma betydelse”), av latinska arcus (”båge”).
Detta är olämpligt, eftersom arcade inte betyder ’samma betydelse’, utan ’rad av valvbågar uppburna av kolonner eller pelare’. Det borde stå så här:
Går detta att åtgärda?
--Andreas Rejbrand (diskussion) 7 juli 2023 kl. 13.01 (CEST)
- Absolut! ✔ En hel del artiklar (exakt EN enligt min utredning) var drabbad. pub Serviette KATT (troligast tom). Taylor 49 (diskussion) 7 juli 2023 kl. 14.58 (CEST)
Röda länkar, trots g-cell
redigeraVarför har grammatikrutan i discipula (som anropar {{la-subst-1-a}}) röda länkar, och inte gröna länkar som i discipulus (som anropar {{la-subst-2-us}})? Båda mallarna använder {{g-cell}}, så resultatet borde vara gröna länkar i båda fallen. -- LA2 (diskussion) 1 augusti 2023 kl. 01.08 (CEST)
- fixat, mallnamnsparameter saknades i
{{grammatik-start}}. Andreasl01 (diskussion) 1 augusti 2023 kl. 17.07 (CEST)
Språklänkar från relaterade ändringar
redigeraSpecialsidan för relaterade ändringar utgår från en kategori. Om den kategorin har språklänkar, så borde väl även relaterade ändringar kunna visa språklänkar till dessa kategoriers relaterade ändringar. Detta vore användbart för kategori:Ukrainska/Alla uppslag, som är en "senaste ändringar" (vad har hänt?) för uppslag på ett givet språk. Jag vill alltså att den ska länka direkt till sin engelska motsvarighet. -- LA2 (diskussion) 2 augusti 2023 kl. 09.55 (CEST)
- Jag förmodar att detta inte går. Den engelska motsvarigheten har inte heller språklänkar. Varför? Det handlar om en "Special:" sida som är utesluten från WikiData. Det som intresserar dig, nämligen ukrainska, matas in genom en HTML-parameter, det är inte ens en del av sidnamnet. Till sist går det inte att transkludera något som skulle innehålla gammaldags interwikimärken. Taylor 49 (diskussion) 2 augusti 2023 kl. 23.14 (CEST)
- Men vi har lyckats få språklänkar från Special:Search/xxyyzz (trots att detta saknas på andra språk, t.ex. en:Special:Search/xxyyzz). Så då tänkte jag att det borde också gå att få från Special:Relatedchanges/Kategori:Ukrainska/Alla_uppslag. Men det är möjligt att jag har en alltför naiv syn på detta. --LA2 (diskussion) 2 augusti 2023 kl. 23.30 (CEST)
- Det var tufft. MediaWiki:Searchmenu-new MediaWiki:Recentchangeslinked-summary. Ny bedömning: det går, men skulle kräva en modul som läser ut WikiBase/WikiData. Förutsatt att det går att anropa en modul därifrån. Taylor 49 (diskussion) 3 augusti 2023 kl. 00.11 (CEST)
Skriptfel
redigeraJag försökte se var felet låg, men hittar det inte. på uppslaget horunge möts jag av röd text: "Luafel i package.lua på rad 80: module 'Modul:sort' not found.n Backtrace: [C]: i funktionen "error" package.lua:80: i funktionen "load" package.lua:99: i funktionen "require" Module:categorize:1: i funktionen "chunk" mw.lua:496: ? [C]: ?"
- Temporärt problem. Har sett sådant tidigare. Taylor 49 (diskussion) 16 augusti 2023 kl. 06.00 (CEST)
Mallar för besläktade ord
redigeraVad tycks? Bra eller dåligt? Jag införde nu på prov en gammal idé från ryska Wiktionary, nämligen att återanvända "besläktade ord" i form av en mall. Första exemplet är ukrainska verbet читати (att läsa), som använder {{uk-besläktade-tjytaty}} (man får inte blanda latinska och cyrilliska bokstäver i sidnamn, därav transkriberingen), som räknar upp ett antal ord med samma stam (-läs-, -чит-). Mallen återanvänds i de blålänkade orden (прочитати, читальня, читач). Man kan jämföra ru:шаблон:родств:чит som har en stor utfällbar ruta med ryska ord besläktade med stammen -чит- (-läs-). Det skulle kunna bli tusentals sådana mallar, en för varje språk och ordstam. Men är det en börda att ha så många sådana mallar, eller en större börda att inte ha dem och i stället upprepa uppräkningen i olika artiklar? -- LA2 (diskussion) 15 augusti 2023 kl. 23.55 (CEST)
- Support. eo:Ŝablono:superrigardo akvejoj sv Men då ska de ligga i en underkategori. Och det borde specificeras ett minimiantal ord för att rättfärdiga en mall. Men varför inte även med bilder och flerspråkig? eo:Ŝablono:superrigardo_ŝakpecoj_univ eo:Ŝablono:superrigardo_nombroj_univ. Taylor 49 (diskussion) 16 augusti 2023 kl. 05.58 (CEST)
Ny syntax för brödtextmallar
redigeraMallarna {{sammansättningar}} och {{besläktade ord}} verkar bara använda 1 parameter, även om man anger flera. Ingen kontroll görs, man får inget felmeddelande. Mallen {{synonymer}} gör en kontroll och sätter anropande artikel i kategori:Ogiltiga parametrar, om parameter 2 finns, men är annars lika. De bara anropar {{länka|{{{1}}}}}. Kanske kan man införa ett alternativ, när 2 parametrar ges (där 1 är en språkkod (sv) och 2 är en lista av ord utan klamrar), så anropas i stället {{länk|{{{1}}}|{{{2}}}}}? Det skulle vara mycket användbart. -- LA2 (diskussion) 16 augusti 2023 kl. 02.05 (CEST)
- Support. Taylor 49 (diskussion) 16 augusti 2023 kl. 05.58 (CEST)
Svårfunnen dokumentation
redigeraI dag försökte jag skriva en mall där en deluppgift var att ta en språkkod som parameter (sv, da) och presentera språktes utskrivna namn (svenska, danska). Jag höll på att leta mig fördärvad innan jag hittade att det heter {{#language:sv}} = svenska. Varför är den informationen så svår att hitta? Var borde den stå? -- LA2 (diskussion) 23 augusti 2023 kl. 17.33 (CEST)
- Modul:lang#Användning. Modul:langfortemplate tjänar ålderdomliga mallar. Nya mallar kör via moduler och direkt via Modul:lang. Din syntax kringgår Modul:lang. Taylor 49 (diskussion) 23 augusti 2023 kl. 19.42 (CEST)
- Den där dokumentationen är långt ifrån lättläst. Vad betyder parametern "go", t.ex.? Det förklaras inte. Är det fel att skriva det kortare {{#language:sv}}? Det står inte. Varför skulle någon vilja skriva det längre {{#invoke:langfortemplate|go|sv}}?
- Om vi vill dra fler medhjälpare till Wiktionary, så måste det bli enklare att bidra, inte svårare. Folk ska kunna skapa mallar, som t.ex. tar språkkod som en parameter och sedan placerar saker i rätt kategori i vars namn språknamnet ingår, exempel [[kategori:bla bla {{#language:{{{1}}}}} bla]]. --LA2 (diskussion) 23 augusti 2023 kl. 21.09 (CEST)
- "go" är namnet på funktionen: mw:Extension:Scribunto#.23invoke.
{{#invoke:langfortemplate|go|jv}}
javanesiska
- medan
{{#language:jv}}
Jawa
- Alla frågor besvarade nu? Att skapa bra mallar är svårt, det är ett faktum bevisat bortom allt tvivel efter 20 år med wikier. Det finns inga genvägar. Vill vi ha en ordbok med hög kvalitet, eller vill vi ha maximal mängd lättskapat skräp? Taylor 49 (diskussion) 23 augusti 2023 kl. 21.26 (CEST)
Röda pluppar - hur?
redigeraNågon som kan förklara lite enkelt hur de röda plupparna dyker upp (de som endast är synliga i redigeringsvy, se exempelvis här. Ursäkta terminologin "röd plupp", de heter säkert något fint tekniskt. Vad jag förstått visar de datorn vart ett ord kan delas upp med bindestreck, men t.ex. i det länkade uppslaget förstör pricken wikilänkningen. 𐏐Frodlekis (Talk💆♂️) 2 november 2023 kl. 15.22 (CET)
- Hej! Om jag öppnar din länk så möts jag av det här: https://privat.rejbrand.se/wtminsting.png. Jag kan inte se några "röda pluppar". Det beror antagligen på att jag har en annan webbläsare än du. Om jag däremot stegar mig genom ordet "syskonskara" med piltangenterna så märker jag att det är ett osynligt tecken mellan "syskon" och "skara".
- Om jag däremot kopierar hela texten och klistrar in den i min texteditor så ser det ut så här: https://privat.rejbrand.se/rteminsting.png. Här ser jag att att länken inte är "syskonskara" utan "syskon" + U+00AD: SOFT HYPHEN + "skara".
- Unicodetecknet U+00AD: SOFT HYPHEN är, precis som du misstänker, en markör för lämplig avstavningsposition. Det är ett bindestreck, liksom - (U+002D: HYPHEN-MINUS) eller ‐ (U+2010: HYPHEN), fast osynligt tills uppritande mjukvara behöver radbryta texten inuti ordet. SOFT HYPHEN skall jämföras med ‑ (U+2011: NON-BREAKING HYPHEN) som är raka motsatsen: ett bindestreck som alltid visas men som, till skillnad från vanliga bindestreck, aldrig tillåter en radbrytning intill (i t.ex. en kod som A‑1 kanske man inte vill ha radbrytning efter strecket).
- Så, till din fråga: texten i filen är alltså "syskon" + U+00AD: SOFT HYPHEN + "skara", d.v.s. en textsträng av längd 12 (inte 11). Det mjuka bindestrecket är osynligt av uppritande mjukvara, men förklarar att mjukvaran vid behov kan avstava här (och då blir strecket synligt sist på övre raden). Tyvärr förstör tecknet wikilänken, så det måste tas bort. Detta kan man göra genom att placera markören direkt till höger om tecknet (direkt till vänster om "skara") och trycka på Backspace. Alternativt kan man placera markören direkt till vänster om tecknet (direkt till höger om "syskon") och trycka på Delete. I en texteditor som min egen är tecknet inte ens osynligt, vilket gör det lättare att arbeta med. --Andreas Rejbrand (diskussion) 2 november 2023 kl. 15.42 (CET)
- Som tillägg till Andreas svar, kan jag förklara när den röda pluppen visas. Pametzma la till det mjuka bindestrecket redan när sidan skapades - jag vet inte hur/varför. I vissa program är det lätt att skapa dom (t.ex. i LibreOffice med Ctrl+-; på Mac med Opt+- (iaf för 15 år sen, när jag använde Mac senast)). Dom fyller ju faktiskt en funktion (se enwp).
- På Wiktionary visas den röda pluppen för att markera osynliga tecken i redigeringsläge när man har aktiverat syntaxmarkering (se skärmbild). Man vet alltså inte exakt vilket tecken det handlar om, för det finns många, många osynliga tecken, och allihop (?) visas som röd plupp. Skalman (diskussion) 2 november 2023 kl. 21.54 (CET)
- Tack så hemskt mycket för de utförliga svaren. 🙏 De här plupparna dyker i princip alltid upp om jag kopierar text utanför redigeringslägen där skrifter som använder right-to-left möter left-to-right. Som ni vet har jag lagt till några tusen ord för jiddisch och hebreiska, men detsamma händer med arabisk skrift. Därför har jag alltid haft för vana att radera dem, men förstår när de dyker upp i ord på LTR-språk att den röda pricken också kan ha en avstavningsfunktion. Intressant att det alltså rör sig om flera olika (!) Unicode-tecken som dyker upp som röda pluppar, och även intressant att inte alla läsare kan se dem (för mig syns de bara när jag redigerar text). Personer som läser i mindre fönster eller med synnedsättning kan alltså tycka dessa är nyttiga, så genomonda kanske de inte är då.
- En följdfråga: plupparna i skriftskiften (ursäkta synvilloordet) - vet ni vilka osynliga tecken (Unicode) det rör sig om där? 𐏐Frodlekis (Talk💆♂️) 3 november 2023 kl. 00.30 (CET)
- Edit: Jag hittade det i Unicode.org. Allt gott 𐏐Frodlekis (Talk💆♂️) 3 november 2023 kl. 00.31 (CET)
- FYI rörde det sig om U+00AD (SOFT HYPHEN) även där. Se denna textsträng jag kopierade från :
- Derived terms
{kind=link}
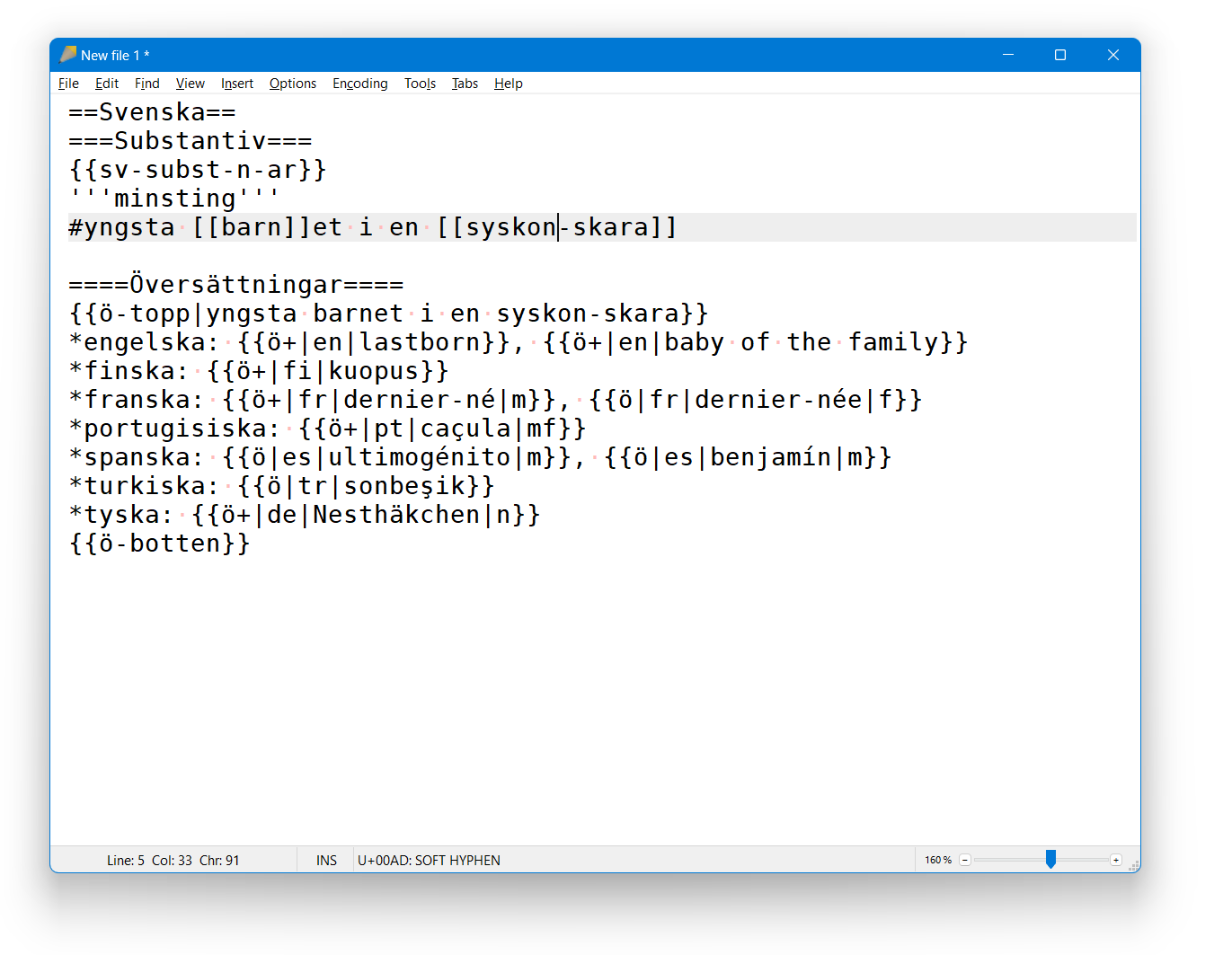{kind=link}
{kind=link}
משפּחהדיק (mishpokhedik) משפּחה־נאָמען (mishpokhe-nomen) פֿאַרצווײַגטע משפּחה (fartsvaygte mishpokhe)
- Och de dyker endast upp när jag hårdkopierat texten från den Läs-sida och klistrar in den i via Redigera-fliken. Inte med "svara"-knappen för ovanstående kommentar. Efter varje jiddiskt ord innan mellanslaget dyker detta tecken upp. Om någon skulle undra. :) 𐏐Frodlekis (Talk💆♂️) 3 november 2023 kl. 00.40 (CET)
- I exemplen som du gav nu, är det U+200E "LEFT TO RIGHT MARK".
- Vid rtl/ltr-skifte kan man förtydliga åt vilket håll det går med hjälp av osynliga unicodetecken: U+200E och U+200F. Se w:en:Right-to-left mark och w:en:Left-to-right mark för information om varför/hur dom kan användas.
- Anledningen till att dom inte dyker upp med svara-funktionen är att syntaxmarkering inte är aktiverat där. Alla dessa osynliga tecken fyller egentligen en funktion, men eftersom det är fruktansvärt svårt för dom flesta av oss att redigera tecken som vi inte kan se, så är det enklast att eliminera så många som möjligt på svwikt (och om man behöver, kan man använda ersättningar som syns i wikitexten:
­ ‎ ‏). Skalman (diskussion) 3 november 2023 kl. 22.52 (CET)

- Tyvärr kan dessa pluppar bland annat vara ett tecken på kopiering från en annan ordbok på nätet. Taylor 49 (diskussion) 3 november 2023 kl. 23.30 (CET)
https
redigeraProjekt Runeberg har äntligen bytt från http:// till https. Efter att jag har uppdaterat källmallarna, har Svenska Wiktionary cirka 2000 externa länkar till den gamla adressen (Special:Länksökning/http://runeberg.org/). De fungerar och blir automatiskt omstyrda till https, men kanske har någon bot-operatör lite långtråkigt och då kunde det vara läge att ändra dessa 2000 hänvisningar. LA2 (diskussion) 26 november 2023 kl. 12.37 (CET)
- Nån annan (du?) har väl fixat en stor andel redan, men nu är resterande 234 sidor inte uppslagssidor (diskussioner mm), så det kanske räcker. Skalman (diskussion) 23 februari 2024 kl. 22.03 (CET)
- Jag ställde frågan ovan 26 november 2023. Sedan lyckades jag återstarta LA2-bot och gjorde själv redigeringen på många sajter, inklusive här den 15 december 2023. --LA2 (diskussion) 24 februari 2024 kl. 00.38 (CET)
Teknisk lösning för att undvika osynliga tecken i artikeltitel?
redigeraSom jag nämnt ett par gånger tidigare, angående de vanligen osynliga tecknen som uppstår vid kopiering av skrift som skrivs från höger till vänster - dessa tecken ställer till det. Nu inte bara för mig. Dessa tecken som kan visas som röda pluppar i redigeringsgranskaren om man trycker på pennan, kan vi på något sätt göra så att de inte kan infogas i översättningsmallen? Och ännu viktigare, så att de inte därifrån osynligt ingår i ett nyskapat uppslags titel och adress? Jag har gjort många ändringar likt denna, och det enda sättet att uppmärksamma det är att inte interwikilänkarna visas till t.ex. en, he, ar Wiktionary. 𐏐Frodlekis (✍) 23 februari 2024 kl. 12.57 (CET) Se t.ex. وثق. 𐏐Frodlekis (✍) 23 februari 2024 kl. 15.17 (CET)
- Jag har fixat så att man inte längre kan skapa sidor som innehåller vissa osynliga tecken. För att skapa وثق måste man nu vara administratör.
- Det här är lurigt, så jag hoppas att jag inte har blockerat nåt som inte bör blockeras.
- Jag borde väl också försöka fixa skriptet där man lägger till översättningar, så att den varnar, blockerar eller autofixar. Osäker på vad som blir bäst. Skalman (diskussion) 27 februari 2024 kl. 21.52 (CET)
Kategorilistenavigering svarar inte korrekt?
redigeraVarför svarar inte uppslaget Kategori:Albanska/Alla uppslag korrekt på mallen {{kategorilistenavigering|sq}}? 𐏐Frodlekis (✍) 26 februari 2024 kl. 12.10 (CET)
- Vad är problemet? Jag tycker att det ser rätt ut. Skalman (diskussion) 26 februari 2024 kl. 21.29 (CET)
- Frodlekis har under tiden upptäckt att mallen är ynkligt konstruerat och kräver ca 10'000 undersidor. Taylor 49 (diskussion) 26 februari 2024 kl. 23.18 (CET)
- Lite så var det, ja. Har fått en del hjälp av ChatGPT så slipper peta in bokstav efter bokstav i alla fall. Dock får jag inte mallen att hitta rätt för dubbelbokstäver som t.ex. dh för albanska. Det är iofs ett mindre problem. 𐏐Frodlekis (✍) 26 februari 2024 kl. 23.30 (CET)
- Mallen fixad. För att det ska fungera, så måste man uppfylla sorteringsreglerna som står specade på Modul:lang/data. Skalman (diskussion) 27 februari 2024 kl. 21.29 (CET)
- Ah, tack, det var där reglerna står. Jag utgick från Appendix alfabet samt engelska Category:Language lemmas. Ska se över resterande nu, men tror jag inte hittade sorteringsfel i övrigt. 𐏐Frodlekis (✍) 27 februari 2024 kl. 21.42 (CET)
- Mallen fixad. För att det ska fungera, så måste man uppfylla sorteringsreglerna som står specade på Modul:lang/data. Skalman (diskussion) 27 februari 2024 kl. 21.29 (CET)
- Frodlekis har under tiden upptäckt att mallen är ynkligt konstruerat och kräver ca 10'000 undersidor. Taylor 49 (diskussion) 26 februari 2024 kl. 23.18 (CET)
Lua 101
redigeraHej! Har försökt sätta mig in i kodning mer och mer, men blir inte klok för varför test 05 inte fungerar på Modul:ca-subst/test? I synnerhet baserat på att test 04 går bra? 𐏐Frodlekis (✍) 19 april 2024 kl. 18.39 (CEST)
- På rad 70 i Modul:ca-subst anropas funktionen
removeAccentmed den odefinierade variabelnsecond_last_1som argument. Argument används sedan i ett anrop till funktionenmw.ustring.gsubsom förväntar sig en textsträng i den positionen, därav felet "Script error during testing: bad argument #1 to 'gsub' (string expected, got nil)" (odefinierade variabler är nil). Lösningen skulle vara att definierasecond_last_1, baserat på namnet förmodar jag att den ska vara sidnamnets näst sista bokstav (på samma sätt somlast_1är sista ochlast_2är de två sista). Det kan även vara bra att se över resten av rad 70, just nu står detplur = removeAccent(second_last_1) .. "os", i de andra elseif-blocken konkateneraspagename,without_last_1ellerwithout_last_2till början avplur, jag misstänker att detsamma ska göras här (troligenwithout_last_2men det har nog du bättre koll på). Andreasl01 (diskussion) 19 april 2024 kl. 20.32 (CEST)- Parallellt med detta har jag fixat problemet. Skalman (diskussion) 19 april 2024 kl. 20.34 (CEST)
- Glömde säga att jag tycker att det är jättebra att du experimenterar och fixar! Skalman (diskussion) 19 april 2024 kl. 20.35 (CEST)
- Parallellt med detta har jag fixat problemet. Skalman (diskussion) 19 april 2024 kl. 20.34 (CEST)
Översättningsmallen trasig
redigeraJag får numera följande meddelande när jag klickar på grönlänkade översättningar för att skapa ny sida: <strong class="error"><span class="scribunto-error" id="mw-scribunto-error-3346f18d">Luafel i Modul:entry på rad 95: parameter "h3" missing for entry_type = "translation".</span></strong> Testat inloggad och utloggad, på två enheter i Safari, bägge med Sonoma 14.5. 𐏐Frodlekis (✍) 7 juni 2024 kl. 16.06 (CEST)
- Kanske relaterat till detta: https://www.mediawiki.org/wiki/Heading_HTML_changes ?
- Tänkte precis skriva att någon behöver uppdatera rubrikreglerna i MediaWiki:Common.css. (se t.ex. sula#Verb, där översättningsrubriken inte längre ligger vid översättningsavsnittet) Andreasl01 (diskussion) 7 juni 2024 kl. 16.52 (CEST)
- Om vi bara tar bort rad 66 (".find('.mw-headline')") i MediaWiki:Gadget-green_links.js tror jag det ska fungera. Men det är nog bäst att låta @Skalman titta på det. Andreasl01 (diskussion) 7 juni 2024 kl. 17.51 (CEST)
- Toppen, tack för svar @Andreasl01. Du väntar vi på det helt enkelt. Inga bekymmer för egen del. 𐏐Frodlekis (✍) 7 juni 2024 kl. 18.02 (CEST)
- Tack båda två för buggrapporten och för hänvisningen till HTML-ändringarna. Tyvärr bestämmer användarens valda tema huruvida den gamla HTML-syntaxen eller den nya ska användas, så jag har anpassat så att bägge stöds. När den gamla syntaxen är helt borttagen från alla teman (om några veckor?), så ska jag förenkla koden så att bara den nya syntaxen stöds.
- Ändringar gjorda hittills:
- Om ni hittar nåt mer som verkar buggigt, säg till så ska jag försöka fixa det också! Skalman (diskussion) 7 juni 2024 kl. 18.45 (CEST)
- Toppen, tack för svar @Andreasl01. Du väntar vi på det helt enkelt. Inga bekymmer för egen del. 𐏐Frodlekis (✍) 7 juni 2024 kl. 18.02 (CEST)
- Om vi bara tar bort rad 66 (".find('.mw-headline')") i MediaWiki:Gadget-green_links.js tror jag det ska fungera. Men det är nog bäst att låta @Skalman titta på det. Andreasl01 (diskussion) 7 juni 2024 kl. 17.51 (CEST)
Har nya svenska artiklar (som olja på duk) slutat att visa "Översättningar..."? @Skalman --LA2 (diskussion) 15 juni 2024 kl. 16.25 (CEST)
- Tack för buggrapporten. Den här var lite krångligare att fixa, men jag tror att det ska funka nu. Om du ändå hittar nåt specialfall som inte funkar, säg till! Skalman (diskussion) 15 juni 2024 kl. 22.34 (CEST)
- Och för att jag ska kunna förenkla när alla teman använder den nya HTML-strukturen - här är ändringen: MediaWiki:Gadget-translation editor add section.js. Skalman (diskussion) 15 juni 2024 kl. 22.36 (CEST)
Funktioner för svenska i wikifunctions
redigeraHej, jag är intresserat av att förbättra svenska och danska lexikaliska data på Wikidata. Jag tänker börja skapa lite funktioner likt [12] och [13] för olika typer av svenska substantiver så det går att böja dem maskinellt. Jag tänker försöka mig på att skapa en funktion för varje av de sex deklinationerna som finns beskrivna här: w:Substantiv#Böjning
Är nån här intresserat av att hänga på och skapa funktioner för svenska?
Se även Wiktionarydiskussion:Stilguide/Grammatik/Svenska/Substantiv So9q (diskussion) 14 juli 2024 kl. 17.43 (CEST)
- OK, det finns funktioner att hita ... men jag blir för närvarande mindre klok av dem. Plus som du skrev på annat ställe går det för närvarande EJ at anropa dessa från andra wikier. Fortsätt gärna diskussionen uteslutande här. Taylor 49 (diskussion) 14 juli 2024 kl. 17.53 (CEST)
- @So9q: [14] f:Z13013 Det verkar att vanliga dödliga användare inte kan redigera funktioner. Men kan en inte ens se källkoden? Taylor 49 (diskussion) 14 juli 2024 kl. 18.05 (CEST)
- Jag minns inte hur, men det går att efterfråga rätt att skapa och ändra funktioner. So9q (diskussion) 14 juli 2024 kl. 22.38 (CEST)
- @So9q: [14] f:Z13013 Det verkar att vanliga dödliga användare inte kan redigera funktioner. Men kan en inte ens se källkoden? Taylor 49 (diskussion) 14 juli 2024 kl. 18.05 (CEST)
- Uppdatering: Nu har jag skapat ett gäng funktioner för svenska substantiv.
- Jag hittade oregelbundna substantiv som inte passade in i Svenska Akademins klassificering så jag skapade två egna klasser. Målet är att det ska vara busenkelt för användaren att välja den funktion som ger rätt böjningsmönster. Se f:User:So9q för en översikt. Jag har testat med alla substantiverna på Kategori:Svenska/Oregelbundna substantiv och vad jag kan se klarar mina 8 pluralfunktioner av alla förekommande fall nu :)
- Jag välkomnar återkoppling och hjälp från er, låt oss skapa funktioner tillsammans som täcker alla former av alla svenska ordklasser, det är kul! :) So9q (diskussion) 17 juli 2024 kl. 04.49 (CEST)
- Fast kan valet av rätt funktion (hos oss: rätt mall) någonsin bli busenkelt? För ryska, ukrainska, belarusiska har vi (jag) i princip gett upp och räknar upp alla böjningsformer i stället för att försöka välja rätt mall (funktion) och utvärdera om det blev rätt. Man måste nog vara infödd modersmålstalare för att kunna bedöma det utan att sitta och detaljkolla mot en pålitlig källa. Om valet vore busenkelt, skulle vi se en massa misstag i stil med pojkerna och ekerarna, när någon som kan språket halvbra har gissat vilken som är rätt böjning. --LA2 (diskussion) 17 juli 2024 kl. 13.59 (CEST)
- Modellen med 4 böjningsmönster för substantiv är ett skämt. Det finns ca 20 till 50, beroende på hur många en vill ha i klassen "övriga". Katten Kategori:Svenska/Oregelbundna substantiv används tyvärr inte konsequent: afton, fängelse, täckelse, öra, öga, hammare, plektrum och många fler. Z17826 koden syns nu och går även att redigera. Vad blir av "glädje", "musik" eller "humus" eller "hummus"? Taylor 49 (diskussion) 17 juli 2024 kl. 17.10 (CEST)
- Jag är benägen att hålla med. Tack för listan. Jag fixade https://www.wikifunctions.org/view/en/Z17721 så den kan hantera afton. So9q (diskussion) 19 juli 2024 kl. 10.17 (CEST)
- Fängelse funkar nu. Täckelse ok. Öra & öga ok.
- hammer och plektrum har flera pluralformer så jag skapade Z18002. Jag skulle vilja varna användaren när den anges som input, men det går inte än att kalla funktioner mellan WF funktioner.
- För singulare tantrum som musik, m.fl. skapade jag Z18006
- Lägg gärna till lämpliga testar om ni hittar ord som funktionerna borde klara av. So9q (diskussion) 19 juli 2024 kl. 15.41 (CEST)
- Modellen med 4 böjningsmönster för substantiv är ett skämt. Det finns ca 20 till 50, beroende på hur många en vill ha i klassen "övriga". Katten Kategori:Svenska/Oregelbundna substantiv används tyvärr inte konsequent: afton, fängelse, täckelse, öra, öga, hammare, plektrum och många fler. Z17826 koden syns nu och går även att redigera. Vad blir av "glädje", "musik" eller "humus" eller "hummus"? Taylor 49 (diskussion) 17 juli 2024 kl. 17.10 (CEST)
- Uppdatering: endast två funktioner kvar tills alla svenska substantiver täcks!
- Svenska substantiver är de mest komplicerade av alla språk som det finns funktioner för än så länge i Wikifunctions vad jag kan se i katalogen. Mycket mera komplicerade av svenska verb som bara har 4 grupper för böjning om jag förstått rätt.
- Nu kanske ni undrar: hur vet användaren vilken funktion som ger rätt böjningsmönster för ett givet substantiv? Det går att skapa en funktion för det om man vill också. Det tänker jag dock inte göra utan lämnar det till en modig och kanske ännu lite mera grammatisk kunnig själ 😀
- Jag tänker använda funktionerna till Wikidata Lexeme Forms där vi behöver skapa nya former för alla nio klasser plus en form for singulare tantrum. So9q (diskussion) 20 juli 2024 kl. 07.34 (CEST)
- Ungefär samma gäller för verb. Det blir ca 20 till 50 mönster, beroende på hur många en vill ha i klassen "övriga". Några jobbiga verb: bli, stjäla, gala, heta, vara (två betydelser), sticka (två betydelser), måste, sluta, be. Och kom på ett jobbigt substantiv till: vimmel. Taylor 49 (diskussion) 21 juli 2024 kl. 22.18 (CEST)
- Jag la till två uttalanden på wikidata:Lexeme:L473175. Dessa behövs när vi skapar funktioner på Wikifunctions framledes så systemet vet hur substantiven funkar i meningar när text ska genereras.
- Mina substantivfunktioner är förresten bara för att hjälpa folk som skapar eller redigerar lexem på Wikidata, inte för att generera text. De måste således inte nödvändigtvis hantera alla udda fall. Jag skapade 3 nya klasser mest för att visa att Svenska Akademien inte gjort klasser som täcker alla vanliga substantiv.
- Jag ogillar personligen när folk utger sig för att vara experter och sakkunniga och sen inte håller måttet.
- Svenska Akademien ligger långt efter när det gäller öppna data om svenskan. Det drabbar dagligen alla som försöker lära sig svenska och saknar bra data och APIer så är pålitliga och lättanvända.
- Danskarna ligger steget före och har skapat öppna data om språket som gagnar samhället. So9q (diskussion) 23 juli 2024 kl. 09.07 (CEST)
- Ditt exempel sticka är intressant. Som syns här finns två lexem redan https://ordia.toolforge.org/search?q=sticka
- Frågan är då hur ett system som skapar meningar ska veta vilken som används?
- Jag har inget bra svar på den frågan.
- Kanske kan systemet fråga om vilken betydelse av sticka som avses av användaren, kanske kan det själv deducere det från input. I dagsläget har vi AIer som chatgpt som endast är byggt på statistik, inte på bra och tillförlitlig språkdata och funktioner skapade av människor med output som går att lita på. So9q (diskussion) 23 juli 2024 kl. 09.15 (CEST)
- Ungefär samma gäller för verb. Det blir ca 20 till 50 mönster, beroende på hur många en vill ha i klassen "övriga". Några jobbiga verb: bli, stjäla, gala, heta, vara (två betydelser), sticka (två betydelser), måste, sluta, be. Och kom på ett jobbigt substantiv till: vimmel. Taylor 49 (diskussion) 21 juli 2024 kl. 22.18 (CEST)
User:Ba(by)bel_AutoCreate
redigeraBoten är blockerad på bara ca 32 wikier. Knepet med {{!}} slutade fungera under år 2022, och sedan dess skapade boten trasiga kategorier. Nu har jag minimalfixat problemet inom Mall:kategorinavigering-användare. Någon lösning som skulle kunna appliceras på MediaWiki:Babel-autocreate-text-main och MediaWiki:Babel-autocreate-text-levels har jag inte hittat, exakt alla försök slog fel. På eo wikitionary finns en bättre mall som inte kräver några parametrar alls. Tyvärr måste även den testa för ns 8. Taylor 49 (diskussion) 9 november 2024 kl. 16.59 (CET)
Mera kompletta och korrekta konjugationstabeller
redigeraJag har inte lyckats hitta in i redigeringen av konjugationstabellerna, där jag har upptäckt felaktigheter och brister som behöver korrigeras, och där hela modi saknas. Ett exempel: under "ta" finns talspråksformen "tatt", vilket väl är ok, antar jag, då den är markerad som sådan, men även "tagandes" under presens particip; varför stoppar man in genitivformen av ett substantiverat adjektiv - eller substantiverad presens particip, om man så vill - i en tabell över verbformer? Däremot saknas såväl "tage" som "toge", samt för den delen även "tagom", som gärna finge förses med tag "åld", men icke desto mindre borde, eller bör, finnas med för referens i sin egenskap av en obsolet, men dock historisk aspekt på det svenska språket. Jämför t.ex. franskan, som oförskräckt tar med ålderdomliga, litterära verbformer, såvitt jag med mina begränsade kunskaper i detta språk kan se. Vad referenser till baskiska och andra obesläktade språk har med saken att göra skulle jag också gärna vilja ha redaktörernas hjälp med att förstå. Tochar (diskussion) 11 november 2024 kl. 08.51 (CET)
- > har inte lyckats hitta in i redigeringen av konjugationstabellerna
{{sv-verb-ar}}
- > upptäckt felaktigheter och brister som behöver korrigeras
- ...
- > hela modi saknas. Ett exempel: under "ta" finns talspråksformen
- ...
- > saknas såväl "tage" som "toge", samt för den delen även "tagom"
- Jag kan inte se några felaktigheter eller brister. Fornsvenska former tas väl med flit inte med.
- > varför stoppar man in genitivformen av ett substantiverat adjektiv - eller substantiverad presens particip
- Det är en obskyr verbform, ej ett substantiverat adjektiv.
- Taylor 49 (diskussion) 11 november 2024 kl. 17.14 (CET)
- @Taylor 49 Bara en kort inflik, pluralformer var i bruk både i tal (dialektalt) och skrift (riksspråkligt) in på mitten av 1900-talet. Det är alltså svenska vi talar om, inte fornsvenska. Se för referens Uppsala Universitets korta artikel här. 𐏐Frodlekis (✍) 11 november 2024 kl. 17.32 (CET)
- ...skriftligen var verbens pluralböjning norm fram tills 1945. Se Språktidningen. 𐏐Frodlekis (✍) 11 november 2024 kl. 17.36 (CET)
- På tal om presensparticip med -s så beskrivs det mer ingående i Svenska Akademiens Grammatik (Volym 2, Particip § 31). Det kan naturligtvis diskuteras om det borde vara en del av mallarna. Själv tycker jag det är onödigt, men det är inte direkt en kulle jag är villig att dö på, om jag säger så. Gabbe (diskussion) 17 november 2024 kl. 05.28 (CET)